판다스의 여러 함수들과 이것저것
1. to_dict()
to_dict() 를 이용하여 시리즈 데이터에서 인덱스와 값을 딕셔너리 key:value 형태로 손쉽게 만들 수 있다.
import pandas as pd
import seaborn as sns
df = sns.load_dataset('penguins')
print(df.value_counts('species'))
print(df.value_counts('species').to_dict())
2. map vs apply
map()
- Series 객체에서 개별 요소에 함수를 적용
- 리스트나 딕셔너리를 매핑할 수도 있음 → 앞서 살펴본 to_dict이랑 같이 활용 가능! (존재하지 않는 키값은 NaN 처리)
- DataFrame 전체에 적용할 수 없음 (Series 전용)
apply()
- Series와 DataFrame 모두 사용 가능
- Series에서는 개별 요소에 적용 (map() 과 유사)
- DataFrame에서는 행(axis=1) 또는 열(axis=0) 단위로 적용 가능
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 행 단위로 합 계산 (axis=1)
print(df.apply(lambda row: row.sum(), axis=1))
# 출력: [5, 7, 9]
# 열 단위로 평균 계산 (axis=0)
print(df.apply(lambda col: col.mean(), axis=0))
# 출력:
# A 2.0
# B 5.0
3. 크기가 다른 시리즈 연산
인덱스가 다른 Series 간 연산
- 동일한 인덱스는 정상 연산
- 일치하지 않는 인덱스는 NaN
4. duplicated() 의 subset 매개변수
duplicated() 는 중복된 행을 찾아내는 함수인데, subset 매개변수를 사용하면 특정 열만 고려하여 중복을 검사할 수 있다.
print(df.duplicated(subset=['A', 'B']))
keep 매개변수와 함께 사용
'first' : 첫 번째 등장 행을 유지하고 나머지를 중복으로 처리 (기본값) (앞의 행이 False)
'last' : 마지막 등장 행을 유지하고 앞의 행을 중복 처리 (앞의 행이 True)
False : 모든 중복 행을 True로 표시
5. groupby() 와 apply() 혼용
groupby() 와 apply() 를 함께 사용하여 그룹별로 사용자 정의 연산을 적용할 수 있음.
즉, groupby()를 사용해 데이터를 그룹화한 후, apply()를 이용해 각 그룹에 원하는 함수나 연산을 적용할 수 있음
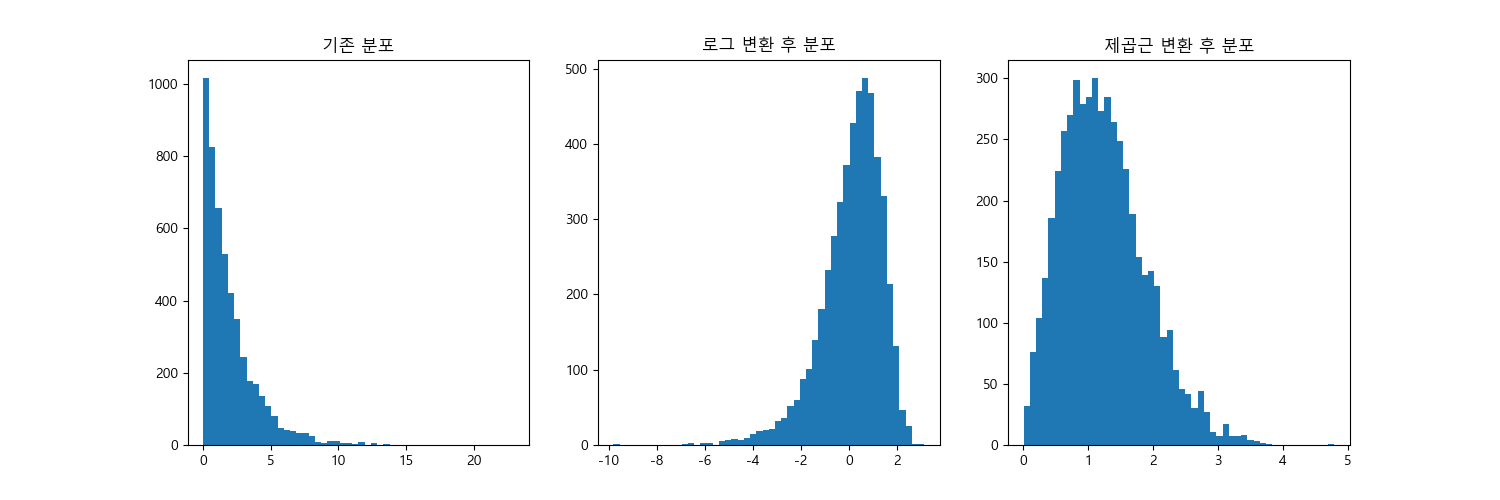
6. 로그 변환이나 제곱근 변환을 통해 오른쪽 긴 꼬리를 가진 분포를 완화하고, 큰 값을 줄일 수 있음
로그 변환과 제곱근 변환은 데이터의 분포를 조정하고, 분석을 용이하게 만들기 위해 사용함
특히, 데이터의 왜도를 줄이고, 정규성을 향상시키거나 이상치 영향을 완화할 때 많이 활용됨
6-1) 로그 변환
- 데이터의 분포를 정규 분포에 가깝게 조정
- 급격한 크기의 차이를 줄여서 분석을 쉽게 만듦
- 이상치의 영향을 줄여서 모델 성능 개선
- 보통 자연로그 또는 상용로그를 사용 (양수 데이터만 가능)
6-2) 제곱근 변환
- 왜도가 심한 데이터의 분포를 조정하여 정규성을 개선
- 로그 변환보다 덜 극단적인 변환으로 0도 포함 가능
- 이상치 영향 감소 (로그보다는 덜 강력)
7. np.diff()
numpy.diff() 함수는 배열의 연속된 요소 간 차이를 계산하는 함수
import numpy as np
arr = np.array([1, 2, 4, 7, 11])
diff_arr = np.diff(arr)
print(diff_arr)
# [1 2 3 4]
8. groupby() 와 transform(), first()
| 함수 | 반환 결과 | 사용 목적 |
| transform() | 원본 행 개수 유지 | 각 행에 그룹별 계산 결과를 적용 |
| first() | 그룹별 첫 번째 행만 반환 | 각 그룹의 첫 번째 행만 가져오기 |
transform()
- 그룹별 연산을 수행한 후 결과를 원래 데이터프레임 크기 그대로 반환
- 각 행에 그룹별 통계값을 적용할 때 유용
import pandas as pd
df = pd.DataFrame({
'Category': ['A', 'A', 'B', 'B', 'C', 'C'],
'Value': [10, 20, 30, 40, 50, 60]
})
df['GroupMean'] = df.groupby('Category')['Value'].transform('mean')
print(df)

first()
- 각 그룹의 첫 번째 행만 반환
- 그룹별 첫 번째 값이 의미 있는 경우 사용
df_first = df.groupby('Category').first()
print(df_first)
