
위의 데이터 프레임으로 모델을 훈련시켜서 허위매물을 색출해보려고 한다.

해당 데이터셋은 불균형 데이터로 타겟 데이터가 전체서 12% 밖에 되지 않는다.
불균형 데이터를 해결하는 방법에는
1. 오버샘플링 : 소수 클래스 데이터를 복제하거나 생성하여 클래스 균형을 맞춤
- Random Oversampling
- SMOTE
- ADASYN
2. 언더샘플링 : 다수 클래스 데이터를 제거하여 클래스 균형을 맞춤
- Random Undersampling
- NearMiss
- Tomek
3. 혼합 기법 : 위의 두 방법들을 혼합해서 사용
추가로 모델 수준에서는 알고리즘 별로 가중치를 조정하거나(그러한 옵션이 있다면) 특화된 알고리즘 (XGBoost, LightGBM) 등을 사용한다. 또 평가지표는 정확도보다 F1 점수(또는 ROC-AUC)를 사용한다.
현재 글에서는 LightGBM과 그리드 서치에서 평가지표를 F1으로 함으로써 이를 해결하려고 한다.
먼저 허위 매물이 무엇인지 그 특징은 무엇인지 알아보자.
허위 매물 : 매매나 전, 월세 계약을 할 매물이 없음에도 불구하고 부동산이 매물을 가지고 있는 것처럼 부동산 중개 플랫폼 등에 거짓 광고를 하는 사례처럼 매물이 없음에도 불구하고 거짓말을 하는 경우
허위 매물의 특징 :
1. 기본적인 정보의 기재가 누락되어 있으면 허위 매물일 수 있다.
→ 가격, 면적, 총 층수, 방 개수, 욕실 개수 등이 null 값일 때 허위매물 비율을 보자
2. 한 부동산에서 너무도 많은 매물들이 여러 곳 등록되어 있다면 허위 매물일 수 있다
→ 중복된 부동산이 존재하는지 확인해보자
3. 누가 봐도 상당히 좋은 조건의 매물임에도 불구하고 시세보다 많이 저렴한 가격이라면 허위 매물일 수 있다.
→ 허위매물은 평수나 해당층 대비 가격이 낮지 않을까?
→ 다만 지역 정보는 없어서 확인을 못한다는 제한이 있다. (지역별로 가격 차이가 날 수 있다)
4. 좋은 매물임에도 불구하고 오랜 시간 방치될리는 없으므로 매물 등록 일자가 너무 오래전이면 허위매물일 수 있다
→ 평수나 가격 대비 오랜 기간이 지났다면 허위매물 비율이 높지 않을까?
하나씩 검증해보자.
1. 기본적인 정보의 기재가 누락되어 있으면 허위 매물일 수 있다.

→ 행에 null 값이 하나라도 있는 매물과 한 개도 없는 매물의 허위매물 비율을 살펴보니 유의미하게 차이가 있었다.
새로운 컬럼을 생성해주자.
df_train['결측치여부'] = df_train.isnull().any(axis=1)
여기서 잠시 떠오르는 생각. 결측치 개수를 나타내는 컬럼을 생성하는 것은 어떨까? 데이터 결측치가 하나인 것보다 2개인게 수상하니깐.

실제 데이터를 살펴보니 모델에 안좋게 작용될 것 같은 느낌이 든다. 그냥 있냐 없냐로 둬도 될듯하다.
2. 한 부동산에서 너무도 많은 매물들이 여러 곳 등록되어 있다면 허위 매물일 수 있다.

확인 결과 중복 매물은 없었다
3. 누가 봐도 상당히 좋은 조건의 매물임에도 불구하고 시세보다 많이 저렴한 가격이라면 허위 매물일 수 있다.

구간별로 허위매물 비율을 구해보았지만 면적이 넓고 가격이 싸다고 해서 허위매물 비율이 높은 경향을 보이진 않았다.
면적이 넓지만 가격은 제일 싼 구간의 비율을 보면 0.064%, 0.07%로 각각 전체 평균 0.091, 0.093% 보다 낮았다.
다만 구간을 어떻게 나누냐에 따라 값이 바뀔 수도 있고 지역이 다른 매물들이 섞여 있을 수 있다
4. 좋은 매물임에도 불구하고 오랜 시간 방치될리는 없으므로 매물 등록 일자가 너무 오래전이면 허위매물일 수 있다
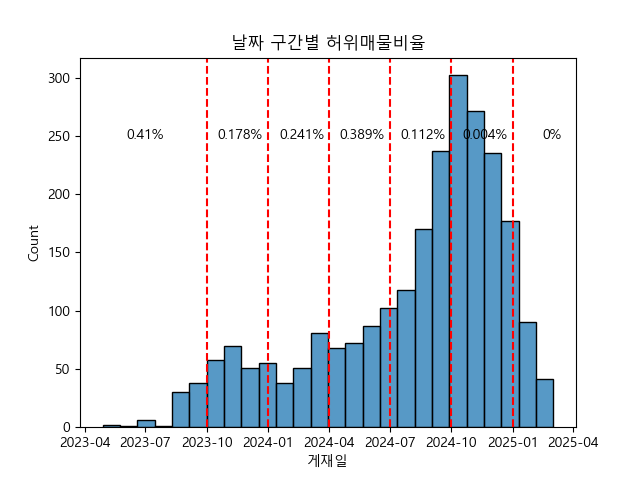
최신 매물보다 9개월 정도 이상 지난 매물들에서 확실히 허위매물 비율이 커지는 경향이 있는 듯하다.
결측치 처리
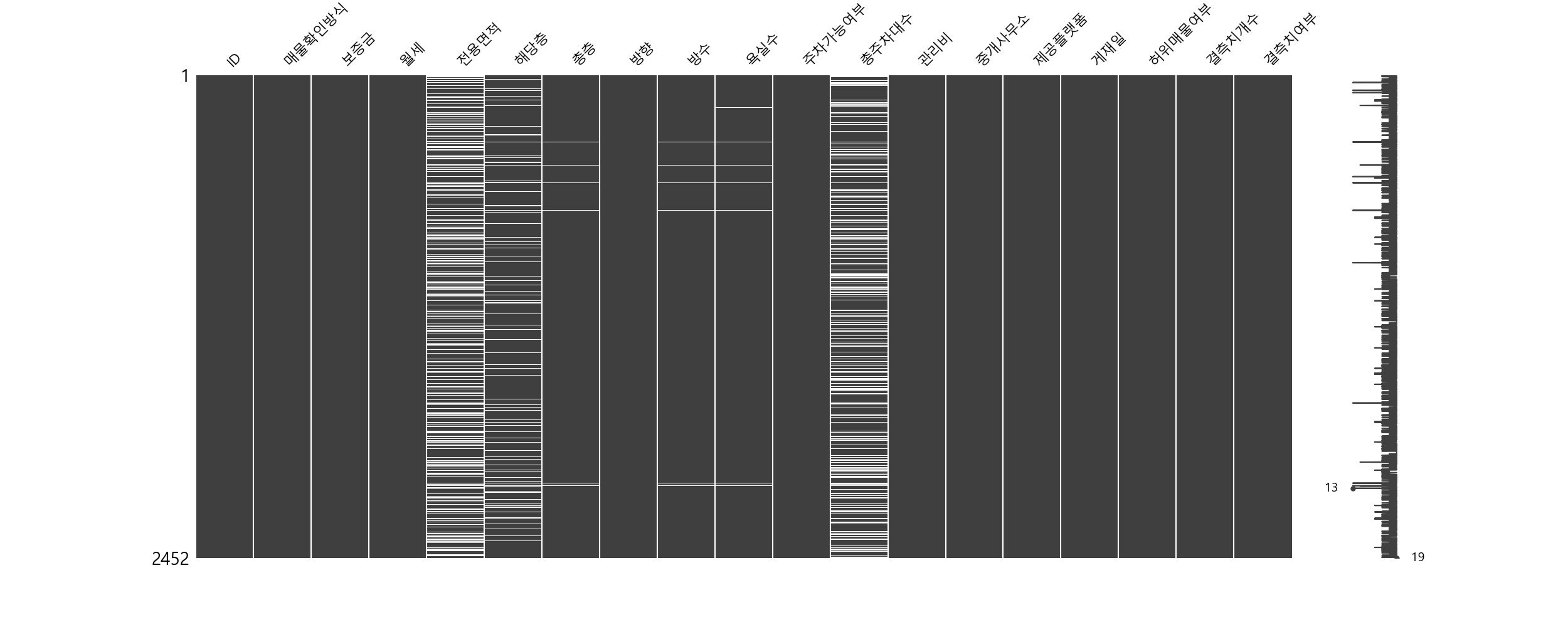
전용면적, 총주차대수가 많은 편이며, 해당 층수가 뒤따르고, 총층, 방수, 욕실수는 적은 결측치를 가지고 있다.
1. 해당층은 총층보다 낮게해서 채울 수 있을 거 같고 또는 해당층과 보증금, 월세가 관련있는지 확인해보자.
2. 총주차대수는 주차가능여부가 False라면 0으로 채울 수 있을 것 같다.
3. 총층과 방수, 욕실수는 결측치 개수가 적으므로 최빈값으로 대체하자
4. 남은 결측치들 처리는?
1. 해당층은 총층보다 낮게해서 채울 수 있을 거 같고.. 그전에 해당층과 보증금, 월세가 관련있는지 확인해보자.
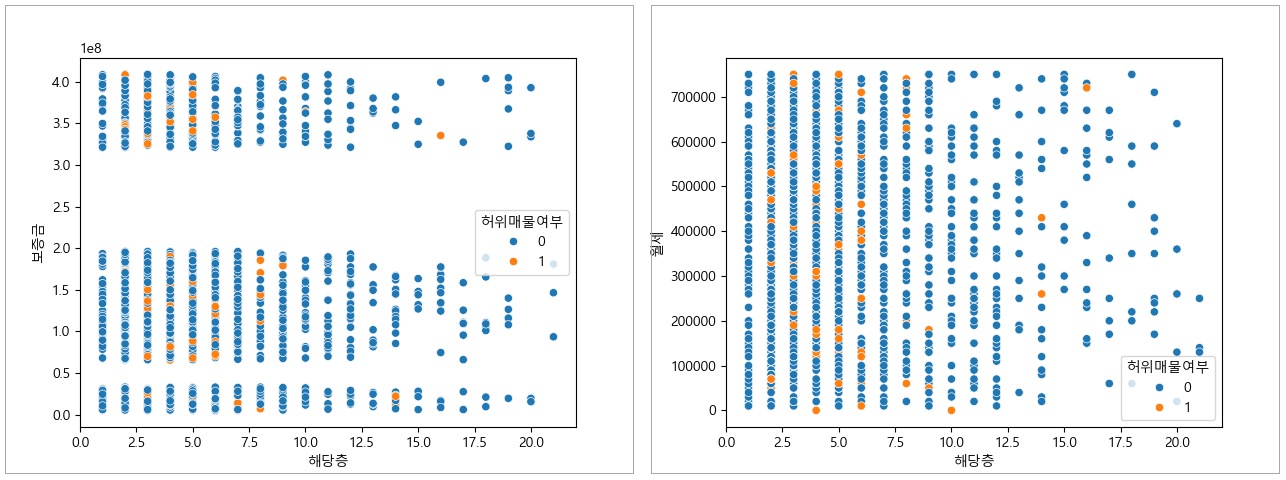
크게 관련이 없어보인다. 월세와 보증금을 이용해 해당층의 결측치를 채우는 것은 어려워 보인다.
대신 총층보다 낮은 값들을 균등분포에서 뽑아 채워넣어보자
# 결측치 처리 함수
def fill_missing_floor(row):
if pd.isnull(row['해당층']): # '해당층'이 결측치인 경우
if not pd.isnull(row['총층']): # '총층' 값이 존재하는 경우
return np.random.randint(1, int(row['총층']) + 1) # 1 ~ 총층 값에서 랜덤 추출
return row['해당층'] # 결측치가 아니면 기존 값 유지
# 데이터프레임의 각 행에 대해 함수 적용
df_train['해당층'] = df_train.apply(fill_missing_floor, axis=1)
나머지 총층이 빈값이라 채워지지 못한 매물들은 평균값으로 대체하자
df_train.loc[df_train['해당층'].isna(), '해당층'] = df_train['해당층'].mean()
2. 총주차대수는 주차가능여부가 False라면 0으로 채울 수 있을 것 같다.

채우기 전에 확인해봐야 할 것이 있다. 바로 주차가 불가능인 매물들의 총 주차대수이다. 주차가 불가능인데도 불구하고 총 주차 대수는 0이 아니라는 것을 알 수 있다. 어떤 데이터인지는 모르니 섣불리 채워넣으면 안될 것 같다. 총 주차 대수는 패스하도록 하자
3. 총층과 방수, 욕실수는 결측치 개수가 적으므로 최빈값으로 대체하자
df_train.loc[df_train['총층'].isna(), '총층'] = df_train['총층'].mode()[0]
df_train.loc[df_train['방수'].isna(), '방수'] = df_train['방수'].mode()[0]
df_train.loc[df_train['욕실수'].isna(), '욕실수'] = df_train['욕실수'].mode()[0]
4. 남은 결측치들 처리는?
LGBM 모델은 결측치를 따로 처리하는 기능이 있다. 그 기능을 위해 남겨두자
그 외
1. 중개사무소

중개사무소 G52lz8V2B9 의 경우 매물 개수가 제일 많았음에도 허위매물을 0개로 허위매물자체를 취급하지 않는다. 이를 해석해보면 허위매물이 고객을 유도하기 위한 사기이므로 이미 매물 개수가 많고 수요가 많을 것이라고 판단되는 중개사무소는 굳이 허위매물을 쓸 필요가 없을 것이다. 보이는 5개 외에 총 279개의 중개사무소들이 있었고 하나를 제외한 나머지는 개수가 적기에 하나로 묶어주자.
df_train['중개사무소'] = df_train['중개사무소'].apply(lambda x: 1 if x == 'G52Iz8V2B9' else 0)
2. 제공플랫폼
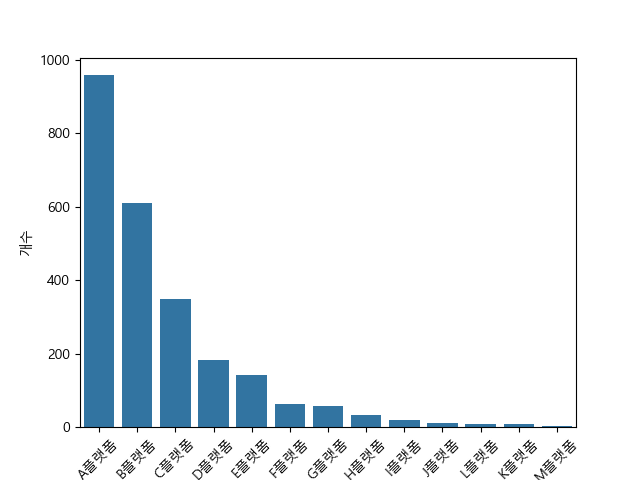
상위 5개를 제외한 나머지들을 갯수가 적으므로 묶어주자
df_train['제공플랫폼'] = df_train['제공플랫폼'].apply(
lambda x: x if x in ['A플랫폼', 'B플랫폼', 'C플랫폼', 'D플랫폼', 'E플랫폼'] else 'O플랫폼')
3. 관리비, 게재일

40 이상인 친구들을 평균값으로 대체해주자. 그리고 게재일로부터 연월일 컬럼을 생성해주자.
# 관리비 이상치 처리
df_train['관리비'] = df_train['관리비'].apply(lambda x: x if x < 40 else 5)
# 게재일 컬럼을 연, 월, 일 컬럼을 분리
df_train['연도'] = df_train['게재일'].dt.year
df_train['월'] = df_train['게재일'].dt.month
df_train['일'] = df_train['게재일'].dt.day
4. 층구간
floor_position = df_train['해당층'] / df_train['총층']
def func(x):
if x <= 0.33: return '저층'
elif x <= 0.66: return '중층'
else: return '고층'
df_train['층구간'] = floor_position.apply(func)
층수와 해당층을 통해 해당층이 어떤 층 구간에 속해있는지 나타내는 컬럼을 만들어보자
남은 결측치는 LightGBM에 맡기도록 하자! (결측치 처리 기능 탑재)
자 이제 모델을 훈련시켜보자! 분류모델에서 성능좋고 인기많은 LightGBM 모델을 사용하려고 한다.
LightGBM(Light Gradient Boosting Machine)이란? Gradient Boosting Framework 중 하나로 속도와 효율성을 극대화하여 대규모 데이터와 고차원 데이터에 적합한 성능을 제공함.
1. 특징
- 빠른 학습 속도
- 대규모 데이터 처리
- 정확도
- 불균형 데이터 지원 ★
2. 주요 하이퍼파라미터
모델 구조 관련
1) num_leaves (20~100)
- 하나의 트리에서 리프 노드의 최대 개수
- 값이 클수록 모델 복잡도가 증가
- 일반적으로 2^(max_depth)보다 작게 설정
2) max_depth (-1 ~ 10)
- 트리의 최대 깊이
- 과적합 방지를 위해 제한을 두는 것이 중요
3) min_data_in_leaf / min_child_samples (10 ~ 200)
- 각 리프 노드에 있어야 하는 최소 데이터 수
- 과적합 방지 역할을 함
4) max_bin:
- 데이터의 값을 이산화할 때 사용할 빈(bin)의 수
- 기본값은 255로, 데이터 세분화 수준을 조절
학습 속도 관련
1) learning_rate (0.001 ~ 0.2)
- 학습률, 작은 값일수록 학습이 느려지지만 더 안정적
- 일반적으로 0.01 ~ 0.1로 설정
2) n_estimators (50 ~ 1000)
- 부스팅 반복 횟수
- 모델의 복잡도를 조정하며, 학습률과 함께 조절
불균형 데이터 처리 관련
1) scale_pos_weight
- 클래스 불균형 비율을 조정 (양성 클래스 샘플수 / 음성 클래스 샘플수)
2) is_unbalance
- 불균형 데이터를 자동으로 감지하여 내부적으로 scale_pos_weight를 설정
정규화 및 과적합 방지
1) subsample (0.6 ~ 1)
- 각 부스팅 반복에서 사용할 데이터 샘플링 비율
2) colsample_bytree (0.6 ~ 1)
- 각 트리 생성 시 사용할 특성 샘플링 비율
3) reg_alpha(L1), reg_lambda (L2)
- L1 및 L2 정규화로 과적합 방지
불필요 컬럼을 제거하고 범주형 데이터의 인코딩을 해준 뒤
타겟 데이터를 나누고 훈련세트와 테스트 세트로 나눠준다.
그 뒤 아무런 설정없이 LGBM 모델을 학습시키고 평가해보자.
# LightGBM 모델
lgb = LGBMClassifier(verbose=-1)
lgb.fit(X_train, y_train)
y_test_pred = lgb.predict(X_test)
# F1-스코어 및 분류 리포트 출력
print("\n테스트 세트 F1-스코어:", f1_score(y_test, y_test_pred))
print("\n분류 리포트:\n", classification_report(y_test, y_test_pred))

F1 스코어가 88로 꽤나 높은 점수를 받았다. is_unbalanced=True 옵션을 주고 다시 학습시켜보자.

같은 점수가 나왔다. 왜 그런지는 잘모르겠다. (scale_pos_weight=10 으로 하니 점수가 소폭 상승했다)
이제 랜덤 서치를 통해 하이퍼 파리미터 튜닝을 진행해보자.
param_distributions = {
'num_leaves': randint(20, 120), # 트리의 리프 노드 최대 개수
'max_depth': randint(-1, 10), # 트리의 최대 깊이
'learning_rate': uniform(0.001, 0.2), # 학습률
'n_estimators': randint(50, 1000), # 부스팅 반복 횟수
'subsample': uniform(0.6, 1), # 데이터 샘플링 비율
'colsample_bytree': uniform(0.6, 1), # 트리 생성 시 사용할 특성 샘플링 비율
'min_child_samples': randint(10, 200) # 리프 노드의 최소 샘플 수
}
# LGBM 모델 정의
lgbm = LGBMClassifier(scale_pos_weight=10)
# RandomizedSearchCV 설정
random_search = RandomizedSearchCV(
estimator=lgbm,
param_distributions=param_distributions,
n_iter=100, # 랜덤 탐색 반복 횟수
scoring='f1', # F1-스코어 기준 최적화
cv=5, # 5-폴드 교차 검증
verbose=1,
n_jobs=-1, # 병렬 처리
)
# 랜덤 서치 실행
random_search.fit(X_train, y_train)
# 최적 하이퍼파라미터 및 성능 출력
print("최적 하이퍼파라미터:", random_search.best_params_)
print("최적 F1-스코어:", random_search.best_score_)
# 최적 모델로 테스트 세트 평가
best_model = random_search.best_estimator_
y_test_pred = best_model.predict(X_test)
# F1-스코어 및 분류 리포트 출력
print("\n테스트 세트 F1-스코어:", f1_score(y_test, y_test_pred))
print("\n분류 리포트:\n", classification_report(y_test, y_test_pred))
# 혼동 행렬 출력
conf_matrix = confusion_matrix(y_test, y_test_pred)
print(conf_matrix)
앞서 매개변수 지정없이 한 모델보다 성능이 낮았다.
그리드 서치를 통해 많은 조합을 진행해보자.
# LGBM 하이퍼파라미터 범위 설정 (그리드 서치) → 경우에 따라 실행 완료까지 12시간 넘게 걸릴 수도 있음
param_grid = {
'num_leaves': [20, 31, 40, 50, 70], # 리프 노드 수
'max_depth': [-1, 5, 7, 10, 12], # 트리 최대 깊이
'learning_rate': [0.01, 0.05, 0.1, 0.15], # 학습률
'n_estimators': [100, 200, 300, 400], # 부스팅 반복 횟수
'scale_pos_weight': [9, 10, 11]
}
# LightGBM 모델 생성
lgb = LGBMClassifier()
# GridSearchCV 설정
grid_search = GridSearchCV(
estimator=lgb,
param_grid=param_grid,
scoring=make_scorer(f1_score), # F1 스코어를 기준으로 최적화
cv=5, # 5-폴드 교차 검증
verbose=1,
n_jobs=-1 # 병렬 처리
)
# 모델 학습
grid_search.fit(X_train, y_train)
# 최적 하이퍼파라미터 및 성능 출력
print("최적 하이퍼파라미터:", grid_search.best_params_)
print("최적 F1-스코어(교차검증):", grid_search.best_score_)
# 최적 모델로 테스트 세트 평가
best_model = grid_search.best_estimator_
y_test_pred = best_model.predict(X_test)
# F1-스코어 및 분류 리포트 출력
print("\n테스트 세트 F1-스코어:", f1_score(y_test, y_test_pred))
print("\n분류 리포트:\n", classification_report(y_test, y_test_pred))
# 혼동 행렬 출력
conf_matrix = confusion_matrix(y_test, y_test_pred)
print(conf_matrix)

0.883으로 소폭 증가하였다.
이제 제출용 데이터를 예측하고 제출해보자.
y_test_pred = best_model.predict(data_cleaned)
df_submission['허위매물여부'] = y_test_pred
df_submission.to_csv('submission.csv', index=False)
0.842 로 꽤 높은 점수가 나온 것 같다.
모델 알고리즘에 대해 조금 더 공부하고 어떤 파라미터를 어떻게 하면 좋을지를 더 이해할 수 있게 해야겠다. 또 전처리를 어떻게 하면 더 좋을지에 대해서도 고민해보고, 불균형 클래스를 처리하는 다른 방식도 시도해봐야겠다. 마지막으로 XGBoos나 랜덤포레스트 같은 다른 모델로도 시도해보자.
'프로젝트' 카테고리의 다른 글
| 신규 고객 맞춤형 프로모션 제안 (0) | 2025.01.03 |
|---|---|
| 스타벅스 마케팅 데이터 분석 (0) | 2025.01.01 |