

susinlee 님의 블로그
Average Selling Price 본문
[문제]
https://leetcode.com/problems/average-selling-price/description/
[풀이]
시계열 조인 문제로 두 가지 방법이 있다. 일반적인 조인 방법(merge)과 투 포인터 접근법을 사용한 방법(merge_asof)이다.
일반적인 조인 방법은 모든 가능한 왼쪽-오른쪽 조합을 계산하는 것으로 O(M x N) 의 시간복잡도를 가지며, 이후 필터링 하는 것은 비용이 너무 크다.
반면, merge_asof는 O(N)의 투 포인터 접근법을 사용해 왼쪽과 오른쪽 데이터를 순회하는데, 이는 시간 정렬이 필요하지만, 시계열 데이터 처리에서는 일반적으로 시간 정렬을 필요로 하기 때문에 큰 문제가 되지 않는다.

1. merge 조인 방법
먼저 일반적인 조인 방법으로 풀어보자. prices와 units_sold를 product_id 열을 키로 병합한다. product_id의 모든 고유값을 가져와야 하므로 left join 해준다.
merged = prices.merge(units_sold, how='left')
병합한 테이블로부터 purchase_date가 start_date와 end_date 사이에 있는 행을 필터링 해준다. 추가로 purchase_date가 빈값인 행도 필터링해준다.
cond1 = merged['purchase_date'].between(merged['start_date'], merged['end_date'])
cond2 = merged['purchase_date'].isna()
merged = merged[cond1 | cond2]
자 이제 병합과 필터링을 끝마친 데이터프레임이 완성됐다. product_id 열로 그룹화한 뒤 각 product_id 별 평단가를 구해보자.
def weighted_mean(df, value, weight):
vs = df[value]
ws = df[weight]
if ws.sum() != 0:
return round((vs * ws).sum() / ws.sum(), 2)
else:
return 0
merged.groupby('product_id').apply(weighted_mean, 'price', 'units', include_groups=False)
product_id로 그룹화된 데이터프레임을 product_id 별로 weighted_mean 함수에 던져준다. 그러면 함수 내부에서 우리가 구하고 싶은 평균단가를 구할 수 있다. units.sum()가 0인 product_id는 0을 반환한다. 아래는 전체 코드다.
def average_selling_price(prices: pd.DataFrame, units_sold: pd.DataFrame) -> pd.DataFrame:
merged = prices.merge(units_sold, how='left')
cond1 = merged['purchase_date'].between(merged['start_date'], merged['end_date'])
cond2 = merged['purchase_date'].isna()
merged = merged[cond1 | cond2]
def weighted_mean(df, value, weight):
vs = df[value]
ws = df[weight]
return round((vs * ws).sum() / ws.sum(), 2) if ws.sum() != 0 else 0
return merged.groupby('product_id').apply(weighted_mean, 'price', 'units', include_groups=False).reset_index(name='average_price')
2. merge_asof 를 이용한 방법
해당 방법을 사용하기 위해서는 먼저 병합할 열을 정렬을 해주어야 한다.
prices = prices.sort_values('start_date')
units_sold = units_sold.sort_values('purchase_date')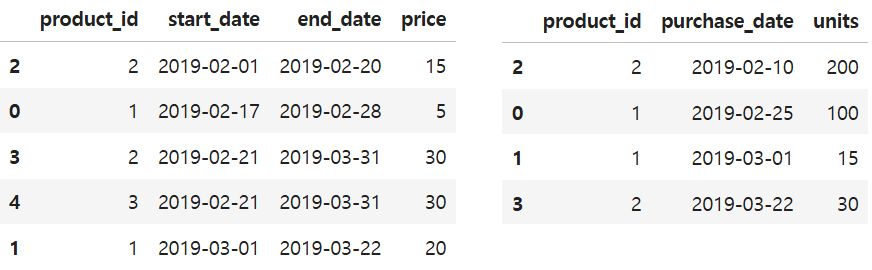
먼저 merge_asof 함수에 대해 알아보자.
pandas.merge_asof(left, right, on=None, left_on=None, right_on=None, by=None, left_by=None, right_by=None, tolerance=None, allow_exact_matches=True, direction='backward')
left, right : 병합할 두 데이터프레임이다.
on : 두 데이터프레임에서 병합할 공통 열 이름이다.
left_on, right on : on 대신 각 데이터프레임에서 사용할 열을 별도로 지정할 수 있다.
by, left_by, right_by : 추가적인 그룹화 기준 열을 지정할 수 있다.
direction : 병합 방향을 설정한다.
- 'backward' : left 값보다 작은 right의 값 중 가장 가까운 값 (기본값)
- 'forward' : left 값보다 큰 right의 값 중 가장 가까운 값
- 'nearest' : 가장 가까운 값 (작거나 크거나 상관없음)
merge_asof 는 항상 left join 만 수행한다. 구매 데이터를 가지고 평단가를 구하는 것이기 때문에 units_sold 기준으로 병합한다.
우리가 해야하는 것은 start_date 열과 purchase_date 열을 키로 product_id 별로 비교해서 병합하는 것이다.
purchase_date 값이 start_date 보다 커야 하니 start_date이 purchase_date 값과 같거나 작은 값 중 가장 가까운 값을 가져오도록 해야한다.
merged = pd.merge_asof(units_sold, prices, by='product_id', left_on='purchase_date', right_on='start_date')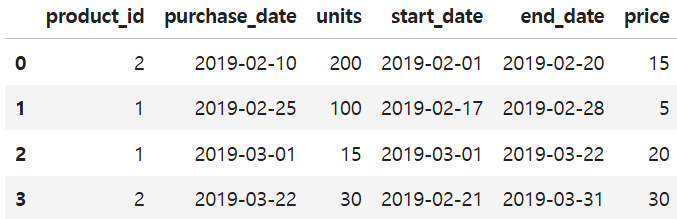
내부적으로 어떻게 돌아간 것인지 한번 시각화해보자.

by 매개변수로 product_id 의 고윳값을 나누고 해당 그룹별로 start_date와 purchase를 정렬된 상태로 나열한다.
purchase_date 값보다 start_date 값이 작거나 같은 것 중 가까운 값을 선택해서 병합된다.
이런 매커니즘으로 병합이 진행된다.
아직 몇가지 작업이 남아있다. purchase_date가 큰 값 중 작은 값이라도 end_date 값보다 커진다면 제외해 주어야 한다. 위의 케이스에서는 그런 경우는 없지만 일반화를 위해 처리해주자.
badprice = merged['purchase_date'] > merged['end_date']
merged.loc[badprice, ['price', 'units']] = 0
앞서 일반 조인과 마찬가지로 데이터프레임을 요구에 맞게 만들어주면 된다.
def weighted_mean(df, value, weight):
vs = df[value]
ws = df[weight]
return round((vs * ws).sum() / ws.sum(), 2) if ws.sum() != 0 else 0
merged = merged.groupby('product_id').apply(weighted_mean, 'price', 'units', include_groups=False).reset_index(name='average_price')
마지막으로 product_id 3인 그룹도 처리해주어야 한다. 해당 그룹은 구매 기록이 없으므로 average_price 를 0으로 처리해주어야 한다.
priceIds = set(prices['product_id'].unique())
soldIds = set(units_sold['product_id'].unique())
missingIds = priceIds.difference(soldIds)
fill = pd.DataFrame({'product_id': list(missingIds), 'average_price': [0]*len(missingIds)})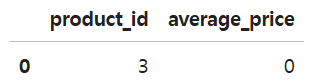
이제 두 테이블을 합쳐주자
pd.concat([merged, fill])
전체코드
def average_selling_price(prices: pd.DataFrame, units_sold: pd.DataFrame) -> pd.DataFrame:
prices = prices.sort_values('start_date')
units_sold = units_sold.sort_values('purchase_date')
merged = pd.merge_asof(units_sold, prices, by='product_id', left_on='purchase_date', right_on='start_date')
badprice = merged['purchase_date'] > merged['end_date']
merged.loc[badprice, ['price', 'units']] = 0
def weighted_mean(df, value, weight):
vs = df[value]
ws = df[weight]
return round((vs * ws).sum() / ws.sum(), 2) if ws.sum() != 0 else 0
merged = merged.groupby('product_id').apply(weighted_mean, 'price', 'units', include_groups=False).reset_index(name='average_price')
priceIds = set(prices['product_id'].unique())
soldIds = set(units_sold['product_id'].unique())
missingIds = priceIds.difference(soldIds)
fill = pd.DataFrame({'product_id': list(missingIds), 'average_price': [0]*len(missingIds)})
return pd.concat([merged, fill])
'코드카타 > SQL, Pandas' 카테고리의 다른 글
| Percentage of Users Attended a Contest (0) | 2024.12.26 |
|---|---|
| Project Employees I (0) | 2024.12.26 |
| Not Boring Movies (0) | 2024.12.25 |
| Confirmation Rate (0) | 2024.12.24 |
| Managers with at Least 5 Direct Reports // agg()와 query() (0) | 2024.12.23 |