
모집단을 조사하든, 표본을 조사하든, 이는 모두 데이터를 분석하는 과정이다. 이번에는 데이터에 대한 기본 개념과 데이터의 유형별로 정리하고 요약하는 방법을 알아보자. 앞서 1장에서 보았던 데이터들은 수치로 표현되었다. 하지만 신약과 위약 혹은 여성과 남성처럼 범주로 나타나는 데이터도 있다. 데이터의 유형에 따라 분석방법이 달라지기 때문에, 데이터를 수집할 때나 분석할 때 데이터의 유형을 명확히 파악하는 것이 중요하다.
데이터의 유형
데이터는 일반적으로 수치형 데이터와 범주형 데이터로 구분된다. 숫자로 나타낼 수 있는 데이터를 수치형 데이터라고 한다. 반면 동전의 앞/뒤, MBTI의 INFP, ENFJ 등과 같이 범주형으로 나타낼 수 있는 데이터를 범주형 데이터라고 한다.
1. 수치형 데이터
- 숫자로 나타낼 수 있는 데이터로, 대소 관계가 있고, 양을 계산할 수 있다.
- 분류:
- 이산형 데이터
- 관측 가능한 값이 셀 수 있는 수치형 데이터.
- 예를 들어, 수강생 수, 동전 던지기 횟수 등이 있다
- 연속형 데이터
- 관측 가능한 값이 연속적인 수치형 데이터.
- 예를 들어, 키, 몸무게, 온도 등이 있다.
- 이산형 데이터
2. 범주형 데이터
- 숫자가 아닌 범주로 나타낼 수 있는 데이터.
- 분류:
- 순위형 데이터
- 범주 간에 순서가 있는 데이터.
- 예를 들어, 잘한다/보통이다/못한다, 만족도 조사(매우 만족/만족/불만족) 등이 있다.
- 명목형 데이터
- 범주 간에 순서가 없는 데이터.
- MBTI(INFP, ENFJ 등), 동전(앞면/뒤면) 등이 있다
- 순위형 데이터
데이터 유형을 올바르게 이해하면, 적합한 분석 방법을 선택할 수 있다.
예를 들어,
- 수치형 데이터는 평균이나 표준편차와 같은 기술통계로 분석할 수 있고
- 범주형 데이터는 빈도나 비율을 활용한 기술통계로 분석할 수 있다.
변수
변수란, 관측값들의 특성이나 성질을 의미한다. 변수(성별, 키, 몸무게)는 대상(사람, 물체, 사건 등)에 따라 변화하거나 달라질 수 있는 값이다. 앞으로 수치형 변수, 범주형 변수 등으로 구분하여 사용할 것이다.
데이터의 경향을 파악하는 두 가지 방법
아무런 처리를 하지 않은 원자료를 단순히 관찰하는 것만으로는 데이터의 전체적인 경향을 파악하기 어렵다. 따라서 데이터를 요약하거나 시각화하여 한 눈에 파악할 수 있는 방법이 필요하다. 이러한 과정을 통해 데이터의 분포와 특성을 보다 효과적으로 분석할 수 있다. 데이터 분석 과정에서는 먼저 데이터의 유형을 파악한 뒤, 데이터가 어떻게 분포되어 있는지를 특정 수치 통해 확인하거나 그래프 등으로 시각화하여 대략적인 경향을 파악하는 것이 일반적이다.
1. 데이터의 경향을 정량적으로 측정하기
평균값과 같이 데이터를 요약하여 특성을 간단히 나타내는 수치를 기술통계량이라고 한다. 기술통계량은 주로 수치형 변수를 대상으로 계산하며, 범주형 변수의 경우, 범주의 빈도나 비율을 활용하여 데이터를 요약하고 설명할 수 있다.
기술통계량은 데이터의 특성을 한눈에 보여줄 수 있지만, 하나의 수치로 요약하는 과정에서 일부 정보가 손실될 수 있다.
예를 들어, 평균값은 데이터의 중심 경향을 나타내지만, 데이터가 얼마나 퍼져 있는지는 알 수 없다. 따라서 데이터의 퍼짐 정도를 나타내는 분산이나 표준편차와 같은 다른 통계량을 함께 살펴보아야 한다. 이처럼 기술통계량은 단일 통계량이 아닌 다양한 통계량을 종합적으로 살펴보는 것이 중요하다.
기술통계량은 크게 다음 두 가지로 구분할 수 있다.
- 대푯값 : 데이터의 중심을 나타내는 값으로, 평균값, 중앙값, 최빈값이 있다.
- 퍼짐 정도 : 데이터가 흩어져 있는 정도를 나타내는 값으로 범위, 분산, 표준 편차, 사분위수가 있다
대표값
표본평균은 전체 관측값들을 모두 더한 후 관측값의 개수로 나누어 계산되며, 데이터의 전체적인 경향을 대변할 수 있는 대표값이다. 하지만 극단적인 값에 크게 영향을 받는다는 단점이 있다. 따라서 데이터에 극단값이 포함된 경우, 표본평균만을 사용하는 것은 적절하지 않을 수 있다.

중앙값을 사용하면 극단값의 영향을 줄일 수 있다. 중앙값은 데이터 값들을 크기 순으로 정렬했을 때 가운데에 위치한 값으로, 극단값에 영향을 받지 않는다는 장점이 있다. 이는 특히 데이터가 비대칭적이거나 이상치가 포함된 경우에 유용하다. 표본 개수가 짝수일 때는 가운데 두 값의 평균값을 사용한다. 가운데 위치한 데이터일 뿐이기에 다른 데이터의 정보는 손실된다는 단점이 있다.
다음으로 최빈값은 데이터에서 가장 빈도가 높은 값으로 정의된다. 최빈값은 범주형 변수에서 유용하게 활용되며, 연속형 변수(주로 이산형)에서도 데이터의 빈도를 나타낼 때 사용된다. 하지만 최빈값은 데이터의 분포를 완전히 설명하지 못할 수 있고, 하나 이상의 최빈값이 존재할 수도 있다.
표본평균과 중앙값, 최빈값 비교

수입 분포와 같은 꼬리가 긴 비대칭 분포에서는 평균값과 중앙값 사이에 차이가 발생한다. 예를 들어, 왼쪽의 그래프처럼 극단적으로 높은 수입을 가진 소수의 데이터(고소득층)가 포함된 경우, 평균값은 중앙값보다 더 크게 나타난다. 이는 평균값이 극단값의 영향을 많이 받기 때문이다. 이러한 상황에서는 중앙값이 대다수 데이터의 대표값으로 더 적합할 수 있다.
반면, 정규분포처럼 좌우가 대칭인 분포에서는 평균값, 중앙값, 최빈값이 모두 비슷할 것이다. 이는 데이터가 대칭적으로 분포되어 있어 각 값이 데이터의 중심을 잘 나타내기 때문이다.
아래 실습 코드들을 실행시키기 전 필요 라이브러리들을 불러오자
import numpy as np
import pandas as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
# 한글 폰트 설정 (예: Windows)
rc('font', family='Malgun Gothic')
# 유니코드 음수 기호가 깨지지 않도록 설정
plt.rcParams['axes.unicode_minus'] = False
대푯값 구하기(파이썬)
df = pd.DataFrame({
'점수': [70, 72, 80, 77, 80]
})
# 평균 구하기
s_mean = df['점수'].mean()
print(s_mean) # 75.8
# 중앙값 구하기
s_median = df['점수'].median()
print(s_median) # 77
# 최빈값 구하기
s_mode = df['점수'].mode()[0]
print(s_mode) # 80
퍼짐 정도
대푯값을 이용하면 데이터가 어디를 중심으로 분포하는지를 알 수 있지만, 데이터가 어느정도로 퍼져있는 지를 파악할 수 없다. 예를 들어, 데이터셋이 모두 평균값이 50이라고 가정하더라도, 한 데이터 셋은 모든 값이 50 근처에 몰려 있을 수 있고, 다른 데이터셋은 값이 10과 90에만 존재할 수도 있다. 이처럼 퍼짐 정도를 나타내는 통계량을 함께 살펴봐야 데이터의 특성을 더 잘 이해할 수 있다.

데이터 퍼짐 정도를 측정하는 기술통계량으로 분산과 표준편차가 있다. 일반적으로 표본을 대상으로 조사하기 때문에 이를 표본분산과 표본표준편차라 부른다. 관측값들이 자료의 중심위치에서 얼마나 떨어져 있는지를 측정하기 위해, 각 관측값에서 평균값과의 차이를 계산한다. 이를 편차라고 한다. 그러나 편차를 단순히 더하면 결과가 0이 되므로, 각 편차를 제곱하여 합산한다. 이 값을 (표본 크기 - 1)로 나누면 분산을 구할 수 있다. 표본이 아닌 모집단의 분산을 구할 때는 n으로 나눠준다.

분산의 주요 특징은 다음과 같다
- 항상 0 이상의 값을 가진다.
- 데이터의 값이 모두 동일할 경우, 분산은 0이 된다.
- 데이터의 퍼짐 정도가 클수록 분산도 커진다.
분산은 데이터를 분석할 때 유용한 척도이지만, 제곱을 취하는 과정에서 데이터의 단위가 제곱으로 변하는 문제가 있다. 이로 인해 데이터가 얼마나 퍼져 있는지 직관적으로 이해하기 어려울 수 있다. 이를 보완하기 위해 분산에 제곱근을 취하여 원래 단위로 복원한 값이 표준편차이다. 표준편차는 데이터의 퍼짐 정도를 보다 직관적으로 이해할 수 있게 해주며, 일반적으로 s 로 표기한다.

하지만 위의 그래프에서 확인할 수 있듯이, 동일한 평균값과 분산을 가지더라도 데이터는 전혀 다른 분포를 가질 수 있다.
이때 데이터를 크기 순서대로 나누어 4개의 구간으로 나눌 때 경계가 되는 값들인 사분위수를 활용할 수 있다. 사분위수를 사용하면 데이터의 퍼짐 정도와 분포 특성을 더 구체적으로 파악할 수 있어 이러한 한계를 보완할 수 있다.
이 외에도 데이터의 분포를 요약적으로 나타내는 방법으로 최댓값과 최솟값의 차이를 의미하는 범위를 계산할 수 있다.
퍼짐 정도 구하기(파이썬)
df = pd.DataFrame({
'점수': [70, 72, 80, 77, 90]
})
# 분산 구하기
s_var = df['점수'].var()
print(s_var) # 62.2
# 표준편차 구하기
s_std = df['점수'].std()
print(s_std) # 7.88
# 범위 구하기
s_range = df['점수'].max() - df['점수'].min()
print(s_range) # 20
# 사분위수 구하기
Q1, Q2, Q3 = df['점수'].quantile([0.25, 0.5, 0.75])
print(Q1, Q2, Q3) # 72, 77, 80
# 평균, 표준편차, 최댓값, 최솟값, 사분위수 한번에 구하기
df.describe()2. 데이터의 경향을 시각적으로 파악하기
데이터를 그래프로 시각화하면 숫자만으로 확인하기 어려운 분포와 경향을 직관적으로 이해할 수 있다. 대표적인 시각화 방법은 다음과 같다.
- 히스토그램 : 데이터의 분포와 빈도를 확인할 수 있다.
- 박스플롯(상자수염그림) : 데이터의 중앙값, 사분위수, 이상치를 시각적으로 나태난다.
- 막대그래프 : 범주형 데이터의 빈도를 비교하는 데 적합하다.

시각화는 데이터를 보다 쉽게 이해하고 분석 방향을 설정하는 데 큰 도움을 준다. 따라서 데이터 분석 초기에 적절한 시각화 기법을 활용하여 데이터의 전반적인 특징을 파악하는 것이 중요하다.
히스토그램, 박스플롯, 막대그래프 그리기(파이썬)
# 데이터 생성
numerical_data = np.random.normal(loc=55, scale=20, size=1000)
categorical_data = ['만족', '만족', '불만족', '만족', '불만족', '만족', '만족', '불만족']
# 1행 3열 그래프 그리기
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
# 히스토그램 생성
sns.histplot(numerical_data, ax=axes[0])
# 박스플롯(상자수염그림) 생성
sns.boxplot(numerical_data, ax=axes[1])
# 카운트플롯 생성 (범주형 데이터의 범주별 빈도 확인)
sns.countplot(x=categorical_data, ax=axes[2])
박스플롯에서 박스 내부의 선은 데이터를 절반으로 나누는 중앙값(제2사분위수, Q2)을 나타내며, 박스의 양 끝은 각각 제1사분위수(Q1)와 제3사분위수(Q3)를 나타낸다.
박스플롯 바깥쪽에 위치한 점들은 이상치를 의미한다. 이상치는 사분위 범위(IQR)를 기준으로 정의되며, IQR은 Q3 - Q1 으로 계산된다. 일반적으로 다음 조건을 만족하는 데이터를 이상치로 간주한다.
- Q1 - IQR x 1.5 보다 작은 값
- Q3 + IQR x 1.5 보다 큰값
이러한 방식으로 이상치를 정의하기도 하고, 데이터의 특성에 따라 다른 기준을 사용할 수도 있다. 예를 들어, 평균과 표준편차를 기준으로 평균에서 ± 2~3배 표준편차를 벗어나는 데이터를 이상치로 정의하기도 한다.
그 외에도 두 수치형 변수 간의 관계를 확인하기 위해 산점도를 사용할 수 있다. 산점도는 데이터의 분포뿐만 아니라 변수 간의 관계(상관관계, 패턴 등)를 시각적으로 파악하는 데 유용하다.
또한, 여러 수치형 변수들 간의 상관관계를 분석할 때는 상관계수를 계산하여 이를 히트맵으로 시각화할 수 있다. 히트맵은 상관계수를 색상으로 표현해 데이터 간의 관계를 한눈에 파악할 수 있도록 도와준다.
이러한 시각화 기법들은 데이터의 숨겨진 관계와 구조를 발견하는 데 도움을 준다.
# seaborn 데이터셋 불러오기
df_iris = sns.load_dataset('iris')
# 산점도 그리기
sns.scatterplot(x='sepal_length', y='petal_length', data=df_iris)

데이터프레임 안의 여러 수치형 변수들의 산점도와 히스토그램을 한번에 그리는 방법도 있다. 범주별로 색상을 다르게 주고 싶다면 hue='범주형 열 이름' 매개변수를 사용하면 된다.
# 페어플롯 그리기
sns.pairplot(df_iris)
# sns.pairplot(df_iris, hue='species')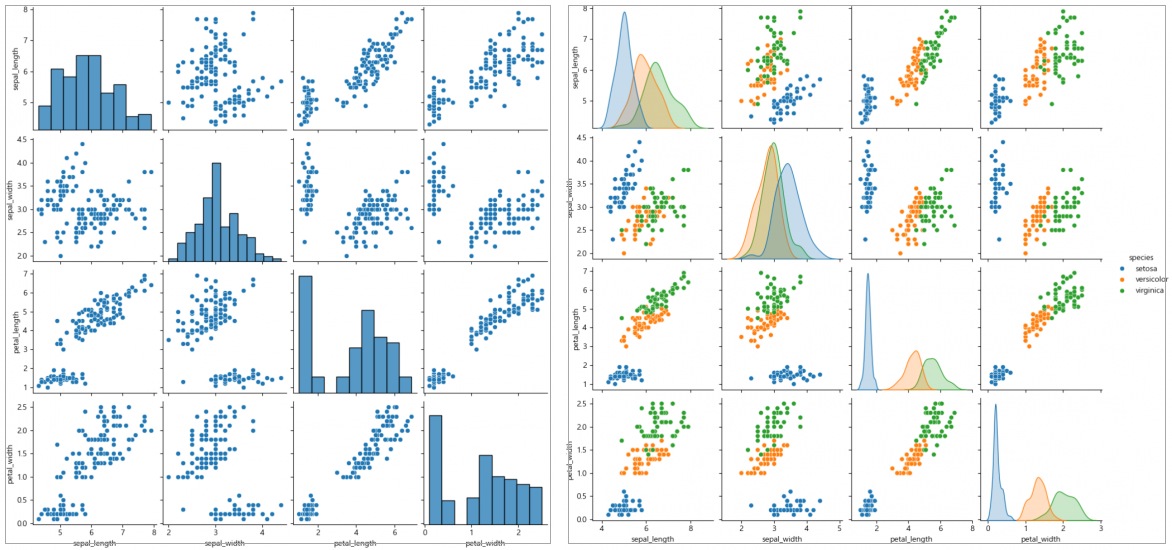
상관계수는 데이터프레임의 corr() 함수를 사용하여 계산할 수 있으며, 결과를 seaborn의 heatmap() 함수를 활용해 시각화할 수 있다. 만약 데이터프레임에 범주형 열이 포함되어 있다면, corr() 함수의 numeric_only=True 매개변수를 사용하여 수치형 열만 선택해 계산해야 한다.
# 상관계수 구하기
iris_corr = df_iris.corr(numeric_only=True)
# 히트맵 그리기
sns.heatmap(iris_corr, annot=True, fmt='.2f', cmap='grey')

여기서 살펴보는 상관 계수는 피어슨 상관 계수로, 두 수치형 변수 간의 선형 관계를 측정하는 통계량이다. 이 값은 -1 과 +1 사이의 값을 가지며 다음과 같은 의미를 가진다
- -1 : 완벽한 음의 선형 관계
- 0 : 선형 관계가 없음
- 1 : 완벽한 양의 선형 관계
주의해야 할 점은 아래 산점도에서 볼 수 있듯이 상관 계수가 0 이라는 것이 두 변수 간에 선형 관계가 없음을 의미할 뿐, 다른 형태의 관계(예: 비선형 관계)가 존재할 가능성을 배제하지 않는다는 점이다. 따라서 상관계수를 계산한 후에는 산점도와 같은 시각화를 통해 두 변수 간의 관계를 추가적으로 확인하는 것이 중요하다.

해당 페이지는 다음 자료들을 참고하여 작성하였습니다.
- 통계101x데이터 분석(아베 마사토)
- 통계학 : 파이썬을 이용한 분석 (인하대학교 통계학과)
- 위키백과
'학습 > 통계학' 카테고리의 다른 글
| 1. 기초 통계학 소개 (0) | 2025.01.10 |
|---|
