

susinlee 님의 블로그
Spotify API와 클러스터링을 활용한 K-pop 추천 알고리즘 본문
프로젝트 명 : 외국 리스너들을 위한 K-POP 추천 알고리즘 개발
프로젝트 목표 : API 사용법을 익히고, PCA와 Kmeans 등의 알고리즘을 활용하여 이에 대한 이해와 활용 역량 강화
배경 : 최근 k-pop 인기로 많은 외국인들이 입문하고 있음
문제 정의 및 원인 :
언어적, 문화적 차이와 더불어 수많은 k-pop 노래가 발매되면서 어디서부터 시작해야 할지 모르는 어려움 존재
해결방안 : 기존에 듣던 노래와 유사한 곡을 추천해주는 시스템이 있다면 보다 쉽게 입문할 수 있을 것
비즈니스 목표

결과물 미리보기 :


목차
1. 데이터셋
2. EDA 및 전처리
3. 변수 선택 및 모델링
4. 인사이트 및 배운점
1. 데이터셋

2. EDA 및 전처리



3. 변수 선택 및 모델링
대표적인 군집화 알고리즘인 KMeans 활용
Why ?
KMeans는 대규모 데이터에서도 빠르게 작동하며, 추천 시스템 구현에 적합한 모델
변수 선택
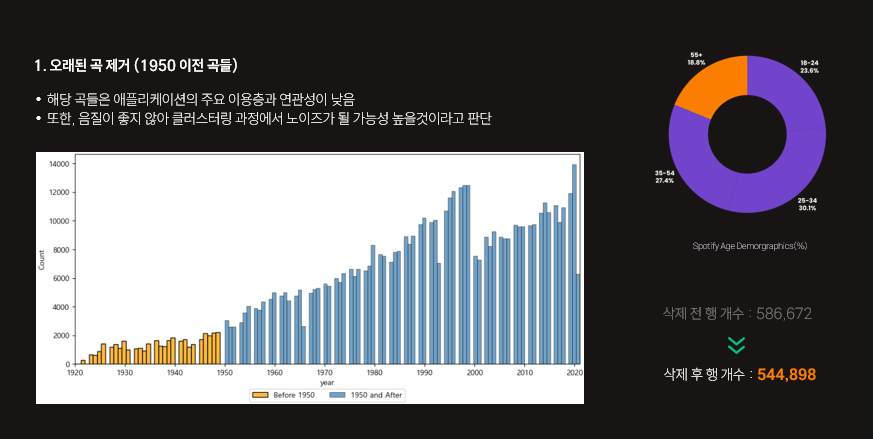
클러스터링의 품질을 높이기 위해 음악적 특성과 연관이 적은 인기도와 곡길이 등의 변수 제외하고 최종적으로 6개의 변수 선택

문제 : KMeans 알고리즘과 같이 유클리드 거리 기반 모델은 다중공선성이 존재할 경우, 사실상 동일한 정보를 중복 반영하게 되어 클러스터가 왜곡될 위험이 있음
해결방안 : PCA

PCA도 KMeans와 마찬가지로 데이터의 스케일을 맞출 필요가 있음
몇몇 변수들에 스케일 차이가 있어 MinMaxScaler를 통해 정규화
KMeans는 비지도 학습으로 k값을 지정해주어야 함.
최적의 k값 찾기

클러스터링 별 특성 비교
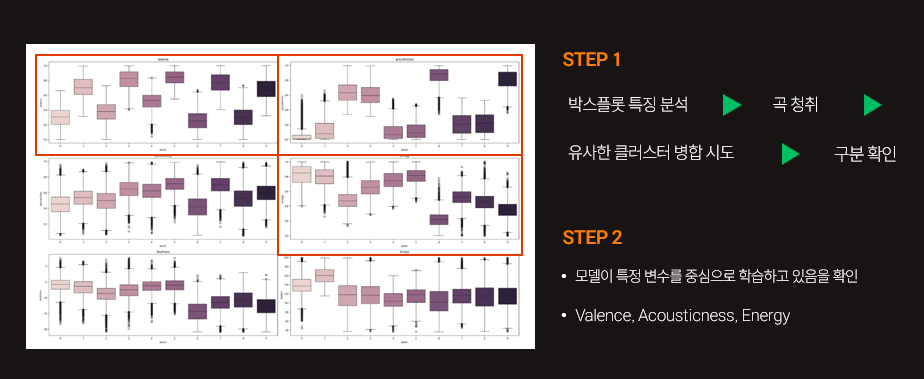
핵심 변수로 시각화 (클러스터 별 특징 및 해당 클러스터의 곡들)


4. 인사이트 및 배운점


한국곡은 어쿠스틱 요소가 낮은 반면, 댄스 적합도와 에너지가 높은 경향을 보임
→ k-pop에서 아이돌 음악의 비중이 크다는 점이 반영된 결과로 해석할 수 있음
오른쪽 그래프를 보면 초기 모델링에서 장단조를 나타내는 mode 변수 (이진 변수)를 모델 학습에 포함
클러스터링 수행 결과, 해당 변수가 클러스터링에 큰 영향을 미쳐 두 개의 그룹으로 분리됨
→ KMeans 알고리즘에서 이진 변수를 직접 활용할 경우 클러스터링 품질 저하 가능성 학습
끝