
susinlee 님의 블로그
재귀 쿼리를 활용한 다양한 계층적 데이터 및 시계열 데이터 다루기 본문
재귀 쿼리의 개념
재귀 쿼리는 트리 구조 데이터 또는 그래프 데이터(네트워크, 경로 탐색)를 다룰 때 사용되는 SQL 기법
기본적으로 자기 자신을 참조하는 방식으로 데이터를 반복적으로 조회할 수 있음
SQL에서 재귀 쿼리는 CTE의 확장 기능이며, WITH RECURSIVE를 사용함
재귀 쿼리의 구조
재귀 쿼리는 세 가지 요소로 구성됨
WITH RECURSIVE recursvie_cte AS (
-- 1. Anchor 쿼리 (기본 시작 데이터)
SELECT 초기값
FROM 테이블
WHERE 조건
UNION ALL
-- 2. Recursive 쿼리 (자기 자신을 참조하여 반복 수행)
SELECT 다음 단계의 값
FROM 테이블
JOIN recursive_cte ON 조인 조건
WHERE 종료 조건
)
-- 3. 최종적으로 데이터를 조회하는 SELECT 문
SELECT * FROM recursive_cte;| 구성요소 | 설명 |
| Anchor Query | 재귀 쿼리의 시작점 (최초 데이터 선택) |
| Recursive Query | 자기 자신을 반복적으로 참조하여 데이터를 확장 |
| Termination Condition | 종료 조건을 설정하여 무한 루프 방지 |
데이터베이스 엔진별 차이점
- PostgreSQL
- WITH RECURSIVE를 완벽하게 지원, 다양한 SQL 기능과 함께 사용 가능
- INTERVAL '1 day' 사용 가능
- 무한 루프 방지를 위한 LIMIT, CYCLE 기능 지원
- MySQL (8.0 이상)
- WITH RECURSIVE를 지원
- PostgreSQL과 유사하게 INTERVAL 사용 가능
- 무한 루프 방지 기능이 부족하여 WHERE depth < N 조건을 추가해야 안전
- SQLite3
- WITH RECURSIVE 지원하지만 INTERVAL 사용 불가능
- DATE(컬럼, '+1 day') 같은 함수 사용 필요
- UNION ALL 만 사용 가능 (UNION 사용 불가능)
- 실행 속도가 다른 DBMS보다 상대적으로 느릴 수 있음
예시 (SQLite3)
1. 조직도 계층 구조 조회
목표: 직원 테이블에서 상사(manager_id)와 직원(id) 관계를 이용해 계층적 조직 구조를 조회
import sqlite3
import pandas as pd
# SQLite 메모리 데이터베이스 연결
conn = sqlite3.connect(":memory:")
cursor = conn.cursor()
# employees 테이블 생성
cursor.execute("""
CREATE TABLE employees (
id INTEGER PRIMARY KEY AUTOINCREMENT,
name TEXT NOT NULL,
manager_id INTEGER,
FOREIGN KEY(manager_id) REFERENCES employees(id)
);
""")
# 직원 데이터 삽입
employees_data = [
(1, "Alice", None), # CEO
(2, "Bob", 1), # Alice의 부하
(3, "Charlie", 1), # Alice의 부하
(4, "David", 2), # Bob의 부하
(5, "Emma", 2), # Bob의 부하
(6, "Frank", 3), # Charlie의 부하
(7, "Grace", 3) # Charlie의 부하
]
cursor.executemany("INSERT INTO employees (id, name, manager_id) VALUES (?, ?, ?);", employees_data)
conn.commit()
query = """
WITH RECURSIVE employee_hierarchy AS (
-- 1️⃣ 최상위 관리자 (CEO) 선택
SELECT id, name, manager_id, 1 AS level
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 2️⃣ 하위 직원들을 재귀적으로 조회
SELECT e.id, e.name, e.manager_id, eh.level + 1
FROM employees e
JOIN employee_hierarchy eh ON e.manager_id = eh.id
)
SELECT * FROM employee_hierarchy ORDER BY level, id;
"""
# Pandas로 결과 조회
table = pd.read_sql(query, conn)
table

2. 항공 경로 탐색
목표:
- flights 테이블을 기반으로 출발지에서 도착지까지의 모든 가능한 경로를 찾음
- A → D 까지 가는 모든 경로를 조회
# flights 테이블 생성
cursor.execute("""
CREATE TABLE flights (
id INTEGER PRIMARY KEY AUTOINCREMENT,
departure TEXT NOT NULL,
arrival TEXT NOT NULL
);
""")
# 항공 경로 데이터 삽입
flights_data = [
(1, "A", "B"),
(2, "B", "C"),
(3, "C", "D"),
(4, "A", "E"),
(5, "E", "F"),
(6, "F", "C")
]
cursor.executemany("INSERT INTO flights (id, departure, arrival) VALUES (?, ?, ?);", flights_data)
conn.commit()
query = """
WITH RECURSIVE flight_path AS (
-- 1️⃣ 출발 공항 A에서 시작
SELECT departure, arrival, 1 AS hops, departure || '->' || arrival AS route
FROM flights
WHERE departure = 'A'
UNION ALL
-- 2️⃣ 도착지를 새로운 출발지로 하여 계속 탐색
SELECT f.departure, f.arrival, fp.hops + 1, fp.route || '->' || f.arrival
FROM flights f
JOIN flight_path fp ON f.departure = fp.arrival
WHERE fp.hops < 5
)
SELECT * FROM flight_path WHERE arrival = 'D';
"""
# Pandas로 결과 조회
table = pd.read_sql(query, conn)
table
3. 빠진 날짜 채우기
목표: sales 테이블에서 누락된 날짜를 채우고, 매출 데이터가 없는 경우 0으로 보정
# sales 테이블 생성
cursor.execute("""
CREATE TABLE sales (
date TEXT PRIMARY KEY,
sales_amount INTEGER
);
""")
# 일부 날짜가 빠진 매출 데이터 삽입
sales_data = [
("2025-03-01", 100),
("2025-03-02", 150),
("2025-03-04", 200),
("2025-03-06", 180)
]
cursor.executemany("INSERT INTO sales (date, sales_amount) VALUES (?, ?);", sales_data)
conn.commit()
query = """
WITH RECURSIVE date_series AS (
-- 1️⃣ 시작 날짜
SELECT MIN(date) AS missing_date FROM sales
UNION ALL
-- 2️⃣ 하루씩 증가하여 날짜 생성
SELECT DATE(missing_date, '+1 day')
FROM date_series
WHERE missing_date < (SELECT MAX(date) FROM sales)
)
SELECT ds.missing_date AS date,
COALESCE(s.sales_amount, 0) AS sales_amount
FROM date_series ds
LEFT JOIN sales s ON ds.missing_date = s.date
ORDER BY ds.missing_date;
"""
# Pandas로 결과 조회
table = pd.read_sql(query, conn)
table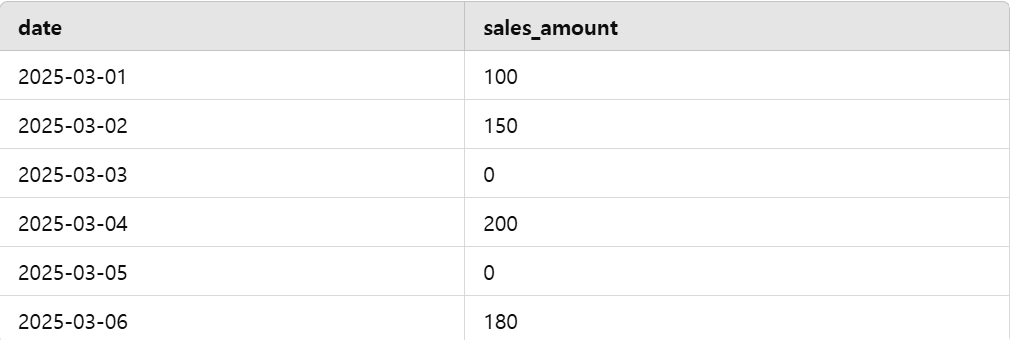
'코드카타 > SQL, Pandas' 카테고리의 다른 글
| 퍼널 분석 - SQL 쿼리로 구현하기 (0) | 2025.03.16 |
|---|---|
| 코호트 분석 - SQL 쿼리로 구현하기 (0) | 2025.03.16 |
| 쿼리 엔진 별로 비교해 보는 날짜 시간 함수 (0) | 2025.03.15 |
| DISTINCT ON, FIRST_VALUE() (0) | 2025.03.12 |
| Supercloud Customer (0) | 2025.03.09 |
'코드카타/SQL, Pandas' Related Articles
more

