

susinlee 님의 블로그
코호트와 리텐션의 구현 (MySQL, Pandas) 본문
데이터 shape: (31465, 4)

코호트 구현하기
고객의 첫 주문 월을 기준으로 Cohort 그룹을 만들고, 각 Cohort 그룹에서 시간이 지남에 따라 활성 사용자 수를 계산하는 SQL 문을 작성하세요.
USER_COUNT_1_MONTH_LATER ~ USER_COUNT_12_MONTH_LATER 까지 계산해야 합니다.
- 각 Cohort 그룹에 대해 1개월 후부터 12개월 후까지의 활성 사용자 수를 추적합니다.
1. 고객별 첫 주문 월 구하기 (코호트 구하기)
WITH cohort AS (
SELECT
customer_id
, DATE_FORMAT(MIN(order_date), '%Y-%m-01') AS first_order_mth
FROM customer_orders
GROUP BY customer_id
)
SELECT * FROM cohort
DATE_FORMAT으로 '%Y-%m-01' 을 해준 이유는 뒤에 날짜 차이를 계산해야하기 때문에 미리 처리해둔 것
여기서 첫 주문 월은 코호트가 된다.
2. 코호트별 활동월별 유저 수 구하기
기존 테이블과 cohort 테이블을 customer_id로 JOIN하고,
first_order_mth와 기존 테이블의 order_date의 월 차이 month_diff를 구한 뒤,
두 컬럼으로 GROUP BY를 해줘서 코호트별로 날짜차이별로 유저 수를 구한다.
12개월 이후까지만 구할 것이므로 필터링을 해준다.
, cohort_counts AS (
SELECT
ch.first_order_mth
, TIMESTAMPDIFF(MONTH, first_order_mth, DATE_FORMAT(co.order_date, '%Y-%m-01')) AS month_diff
, COUNT(DISTINCT co.customer_id) AS user_cnt
FROM customer_orders co
JOIN cohort ch
ON co.customer_id = ch.customer_id
WHERE TIMESTAMPDIFF(MONTH, first_order_mth, DATE_FORMAT(co.order_date, '%Y-%m-01')) < 13
GROUP BY first_order_mth, month_diff
)
SELECT * FROM cohort_counts
3. CASE WHEN 문으로 피벗 구현하기
각 코호트(first_order_mth)별로 GROUP BY를 해준 후,
month_diff = 0 ~ 12 일 때, user_cnt로 아닐 때에는 0으로 해줘서 SUM으로 집계를 해준다.
다음, COALESCE로 혹시 모를 NULL값을 처리해준다.
SELECT
first_order_mth
, COALESCE(SUM(CASE WHEN month_diff = 0 THEN user_cnt ELSE 0 END), 0) AS cohort_user_count
, COALESCE(SUM(CASE WHEN month_diff = 1 THEN user_cnt ELSE 0 END), 0) AS user_count_1_month_later
, COALESCE(SUM(CASE WHEN month_diff = 2 THEN user_cnt ELSE 0 END), 0) AS user_count_2_month_later
, COALESCE(SUM(CASE WHEN month_diff = 3 THEN user_cnt ELSE 0 END), 0) AS user_count_3_month_later
, COALESCE(SUM(CASE WHEN month_diff = 4 THEN user_cnt ELSE 0 END), 0) AS user_count_4_month_later
, COALESCE(SUM(CASE WHEN month_diff = 5 THEN user_cnt ELSE 0 END), 0) AS user_count_5_month_later
, COALESCE(SUM(CASE WHEN month_diff = 6 THEN user_cnt ELSE 0 END), 0) AS user_count_6_month_later
, COALESCE(SUM(CASE WHEN month_diff = 7 THEN user_cnt ELSE 0 END), 0) AS user_count_7_month_later
, COALESCE(SUM(CASE WHEN month_diff = 8 THEN user_cnt ELSE 0 END), 0) AS user_count_8_month_later
, COALESCE(SUM(CASE WHEN month_diff = 9 THEN user_cnt ELSE 0 END), 0) AS user_count_9_month_later
, COALESCE(SUM(CASE WHEN month_diff = 10 THEN user_cnt ELSE 0 END), 0) AS user_count_10_month_later
, COALESCE(SUM(CASE WHEN month_diff = 11 THEN user_cnt ELSE 0 END), 0) AS user_count_11_month_later
, COALESCE(SUM(CASE WHEN month_diff = 12 THEN user_cnt ELSE 0 END), 0) AS user_count_12_month_later
FROM cohort_counts
GROUP BY first_order_mth
리텐션 구현하기

Retained(%) 행에서 각 Month 별로 분모에 오는 유저 수가 다른 것에 유의해야한다.
1. 위의 cohort_counts 테이블에서 첫 주문 월(코호트)만 필터링 해주자.
, eligible_cohort_base AS (
SELECT
first_order_month,
user_count AS cohort_size
FROM cohort_counts
WHERE month_diff = 0
)
SELECT * FROM eligible_cohort_base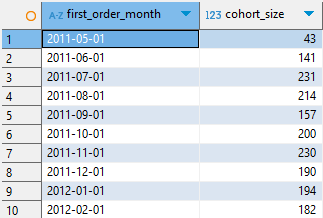
2. 리텐션의 분모 구하기
0부터 12까지의 값을 가지는 N 컬럼 테이블을 만들고,
eligible_cohort_base 테이블(ec1)과 CROSS JOIN을 해준다.
다음, 코호트와 코호트 사이즈 컬럼을 가져온 뒤,
세 번째 컬럼으로 상관서브쿼리를 이용하여 각 개월 수 이후별 분모를 구해준다.
cumulative_base AS (
SELECT
ec1.first_order_month,
ec1.cohort_size,
(SELECT SUM(cohort_size)
FROM eligible_cohort_base ec2
WHERE TIMESTAMPDIFF(MONTH, ec2.first_order_month, ec1.first_order_month) >= N
) AS base_for_monthN,
N AS 'N(month_diff)'
FROM eligible_cohort_base ec1
JOIN (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL
SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL
SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12
) nums
)
SELECT * FROM cumulative_base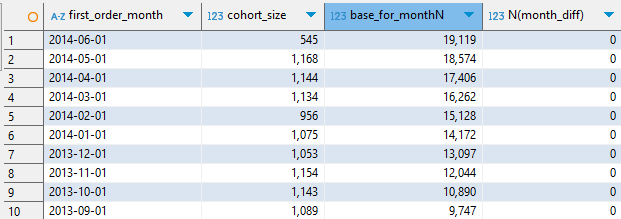
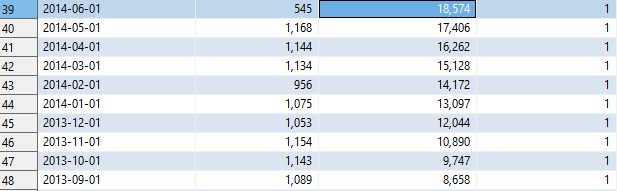
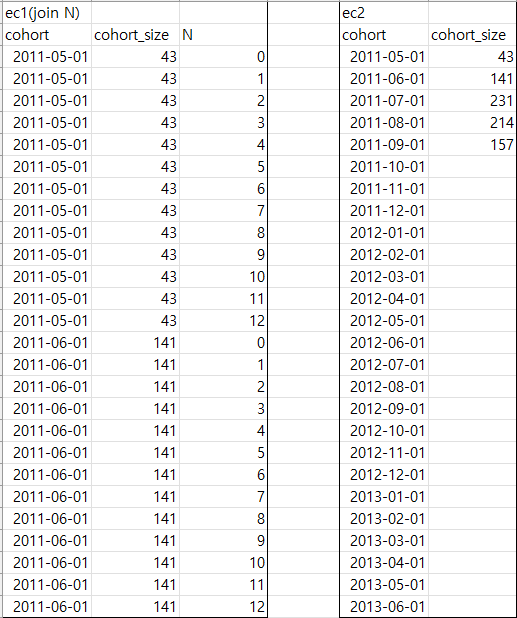
상관서브쿼리는 다음과 같은 프로세스로 동작한다.
nums 테이블과 JOIN한 ec1 테이블을 기준으로 한 행씩 ec2에서 던져서 처리가 되는데,
ec1의 first_order_month에서 ec2의 first_order_month를 빼주는데, 이 차이가 해당 ec1 행의 N보다 커야 한다.
코호트 2011-05-01의 경우, ec2의 first_order_month(cohort) 차이가 0 (N)보다 크거나 같은 행이
ec2에서 제일 위의 하나 뿐이므로, 첫 번째 행의 43(SUM)을 가져오게 된다. (나머지는 - 이므로 생략)
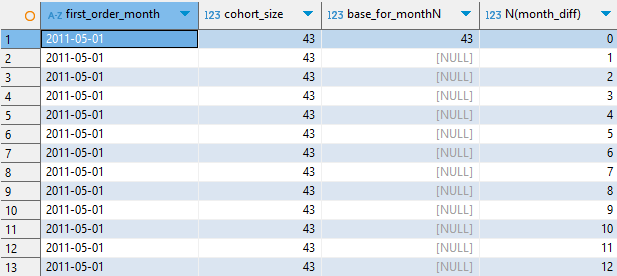
두 번째 코호트인 2011-06-01의 경우, 첫 번째 행을 살펴보자
ec1 first_order_month (2011-06-01) 에서 ec2의 각 행의 first_order_month 빼주면
2011-05-01의 경우 1
2011-06-01의 경우 0
나머지는 - 가 나오게 된다.
이때 첫 번째 행의 N은 0이므로, 두 행의 cohort_size를 가져오게 되는데, 더하면 184가 된다.
두 번째 행의 경우 N은 1이므로, 2011-05-01의 cohort_size만 가져오게 되고, 이는 43이 된다.
따라서 2011-06-01 코호트의 경우 아래와 같은 테이블이 된다.
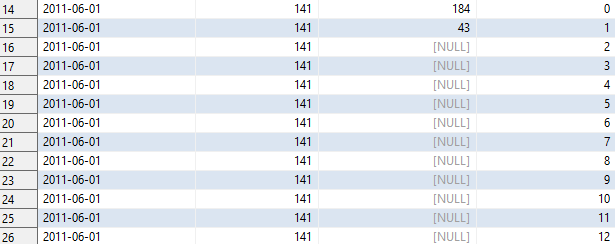
3. 리텐션의 분자 구하기
다시 앞서 코호트 분석할 때 cohort_counts 테이블로 돌아가서,
month_diff 별로 user_count를 더해준다.
단, 12개월 이후까지만 구할 것이므로 WHERE절에서 필터링해준다.
-- 분자 집계
retention_sum AS (
SELECT
month_diff,
SUM(user_count) AS retained_users
FROM cohort_counts
WHERE month_diff BETWEEN 0 AND 12
GROUP BY month_diff
)
SELECT * FROM retention_sum
ORDER BY month_diff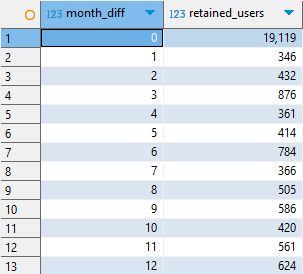
4. 최종 리텐션률 계산
하나의 행으로 구현할 것이기 때문에, CASE WHEN 문을 통해 각 컬럼을 채워넣어야 한다.
분모와 분자를 집계한 테이블을 통해 각 month_diff 별 (분자 / 분모)를 계산해줘야 하므로,
먼저, cumulative_base 테이블과 retention_sum 테이블을 month_diff 컬럼을 기준으로 병합해준다.
→ 앞의 N(month_diff)를 month_diff로 변경해주자.
다음, 각 컬럼마다 month_diff 조건을 걸어서 MAX값을 통해 분모를 가져오고, 마찬가지로 분자도 가져와서 리텐션률을 계산한다.
final AS (
SELECT
'Retained(%)' AS segment,
NULL AS users,
'100.00%' AS month0,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 1 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 1 THEN c.base_for_monthN END), 2), '%') AS month1,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 2 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 2 THEN c.base_for_monthN END), 2), '%') AS month2,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 3 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 3 THEN c.base_for_monthN END), 2), '%') AS month3,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 4 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 4 THEN c.base_for_monthN END), 2), '%') AS month4,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 5 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 5 THEN c.base_for_monthN END), 2), '%') AS month5,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 6 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 6 THEN c.base_for_monthN END), 2), '%') AS month6,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 7 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 7 THEN c.base_for_monthN END), 2), '%') AS month7,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 8 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 8 THEN c.base_for_monthN END), 2), '%') AS month8,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 9 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 9 THEN c.base_for_monthN END), 2), '%') AS month9,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 10 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 10 THEN c.base_for_monthN END), 2), '%') AS month10,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 11 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 11 THEN c.base_for_monthN END), 2), '%') AS month11,
CONCAT(ROUND(100.0 * MAX(CASE WHEN r.month_diff = 12 THEN r.retained_users END) /
MAX(CASE WHEN c.month_diff = 12 THEN c.base_for_monthN END), 2), '%') AS month12
FROM retention_sum r
JOIN cumulative_base c ON r.month_diff = c.month_diff
)
SELECT * FROM final
5. 최종 테이블 구현하기 (절대값 + 비율)
SELECT
'All Users' AS Segment
, SUM(CASE WHEN month_diff = 0 THEN retained_users END) AS Users
, SUM(CASE WHEN month_diff = 0 THEN retained_users END) AS Month0
, SUM(CASE WHEN month_diff = 1 THEN retained_users END) AS Month1
, SUM(CASE WHEN month_diff = 2 THEN retained_users END) AS Month2
, SUM(CASE WHEN month_diff = 3 THEN retained_users END) AS Month3
, SUM(CASE WHEN month_diff = 4 THEN retained_users END) AS Month4
, SUM(CASE WHEN month_diff = 5 THEN retained_users END) AS Month5
, SUM(CASE WHEN month_diff = 6 THEN retained_users END) AS Month6
, SUM(CASE WHEN month_diff = 7 THEN retained_users END) AS Month7
, SUM(CASE WHEN month_diff = 8 THEN retained_users END) AS Month8
, SUM(CASE WHEN month_diff = 9 THEN retained_users END) AS Month9
, SUM(CASE WHEN month_diff = 10 THEN retained_users END) AS Month10
, SUM(CASE WHEN month_diff = 11 THEN retained_users END) AS Month11
, SUM(CASE WHEN month_diff = 12 THEN retained_users END) AS Month12
FROM retention_sum
UNION ALL
SELECT * FROM final
리텐션 구현하기 개선방안
분모 계산 과정을 다음과 같은 쿼리로 더 깔끔하게 구현할 수 있다.
-- 4. 각 코호트의 Month0 인원 (기준 유저 수)
cohort_base AS (
SELECT
first_order_month,
user_count AS cohort_size
FROM cohort_counts
WHERE month_diff = 0
),
-- 5. MonthN까지 충분히 지난 코호트만 남겨서 monthN별 분모 계산 (cumulative base)
cumulative_base AS (
SELECT
N AS month_diff,
SUM(cohort_size) AS base_for_monthN
FROM cohort_base cb
JOIN (
SELECT 0 AS N UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL
SELECT 4 UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL
SELECT 8 UNION ALL SELECT 9 UNION ALL SELECT 10 UNION ALL SELECT 11 UNION ALL SELECT 12
) nums
ON TIMESTAMPDIFF(MONTH, cb.first_order_month, (SELECT MAX(first_order_month) FROM cohort_base)) >= N
GROUP BY N
)
SELECT * FROM cumulative_base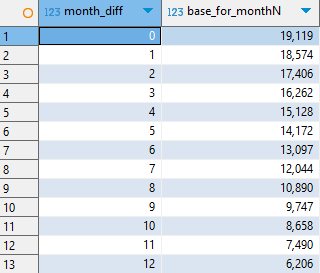
Pandas로 구현하기
코호트 분석
df['order_date'] = pd.to_datetime(df['order_date'])
# 1. 고객별 첫 주문월 (코호트)
df['first_order_month'] = df.groupby('customer_id')['order_date'].transform(lambda x: x.min().to_period('M').to_timestamp())
# 2. 주문월
df['order_month'] = df['order_date'].dt.to_period('M').dt.to_timestamp()
# 3. Month Diff 계산
df['month_diff'] = ((df['order_month'].dt.year - df['first_order_month'].dt.year) * 12 +
(df['order_month'].dt.month - df['first_order_month'].dt.month))
# 4. 유저 수 집계
cohort_pivot = (
df.groupby(['first_order_month', 'month_diff'])['customer_id']
.nunique()
.reset_index()
.pivot(index='first_order_month', columns='month_diff', values='customer_id')
)
cohort_pivot
리텐션율 계산
데이터 셋의 마지막 날짜를 계산한다. 추후 리텐션 분모를 구할 때 쓰일 예정
# 4. 기준 날짜: 데이터셋의 마지막 날짜
max_order_month = test['order_month'].max()
max_order_month
# Timestamp('2014-06-01 00:00:00')
코호트별 month_diff(활동월)별 잔존 유저 수 계산
# 5. 각 month_diff별로 잔존 유저 수 계산
cohort_counts = (
test.groupby(['first_order_month', 'month_diff'])['customer_id']
.nunique()
.reset_index()
)
cohort_counts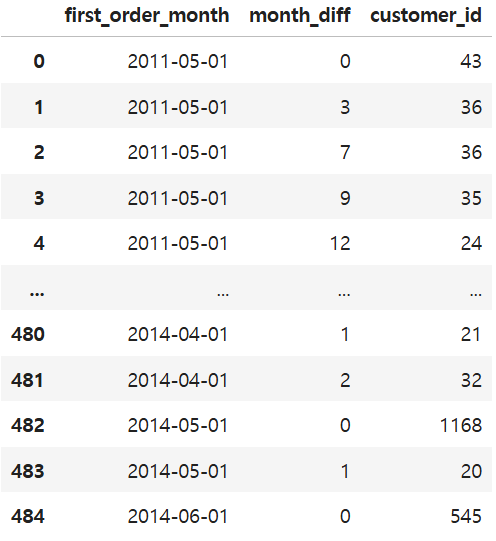
# 6. month0 기준 코호트 크기 추출
cohort_sizes = (
cohort_counts[cohort_counts['month_diff'] == 0]
.set_index('first_order_month')['customer_id']
)
cohort_sizes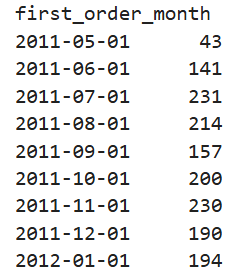
# 7. 각 month_diff에 대해, 해당 월까지 도달한 코호트만 필터링하여 분모 계산
retention_table = {}
for month in range(13): # Month0 ~ Month12
# MonthN까지 시간이 흐른 코호트만 필터링
eligible_cohorts = cohort_sizes[cohort_sizes.index + pd.DateOffset(months=month) <= max_order_month]
base_users = eligible_cohorts.sum()
print(base_users, end=', ')
# 분자: 해당 month_diff에 해당하는 유저 수
retained_users = cohort_counts[
(cohort_counts['month_diff'] == month) &
(cohort_counts['first_order_month'].isin(eligible_cohorts.index))
]['customer_id'].sum()
print(retained_users)
# 리텐션률 계산
retention_table[f'Month{month}'] = [round(100 * retained_users / base_users, 2) if base_users > 0 else None]
# 결과 DataFrame으로 변환
retention_df = pd.DataFrame(retention_table, index=['Retained(%)'])
retention_df = retention_df.astype(str)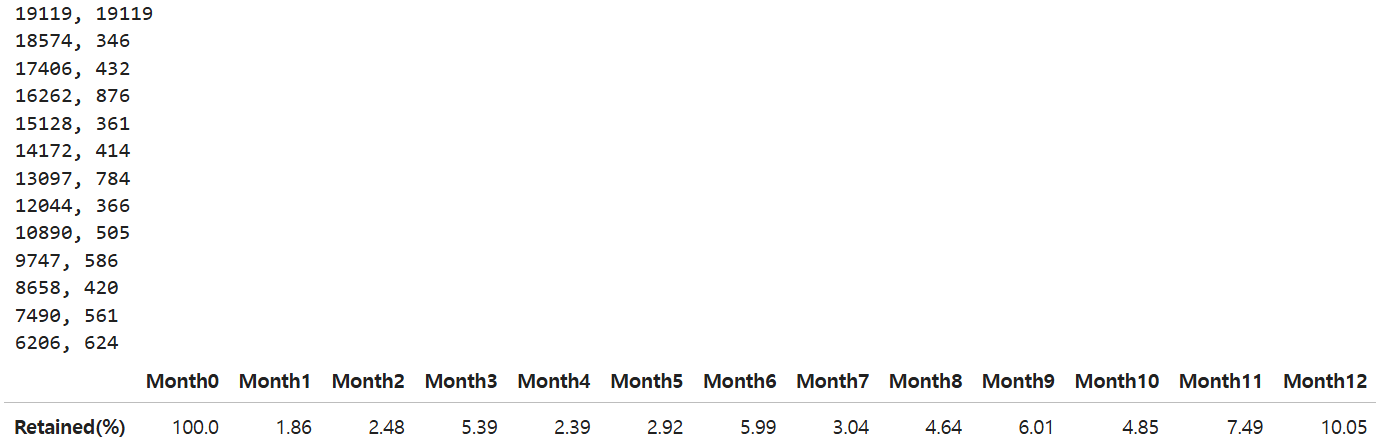
# 최종. All Users: 각 month_diff별 유저 수 합 (분자 기준과 동일)
all_users_counts = {}
for month in range(13):
count = cohort_counts[cohort_counts['month_diff'] == month]['customer_id'].sum()
all_users_counts[f'Month{month}'] = [count]
# DataFrame 생성
all_users_df = pd.DataFrame(all_users_counts, index=['All Users'])
# Retained(%)와 결합
retention_full_df = pd.concat([all_users_df, retention_df])
retention_full_df
'코드카타 > SQL, Pandas' 카테고리의 다른 글
| 문자열 관련 함수, 최적화 및 안정성 (0) | 2025.04.02 |
|---|---|
| 쿼리 작성 가이드 및 최적화 (0) | 2025.03.26 |
| SQL로 조합 생성하기 (0) | 2025.03.18 |
| 퍼널 분석 - SQL 쿼리로 구현하기 (0) | 2025.03.16 |
| 코호트 분석 - SQL 쿼리로 구현하기 (0) | 2025.03.16 |


