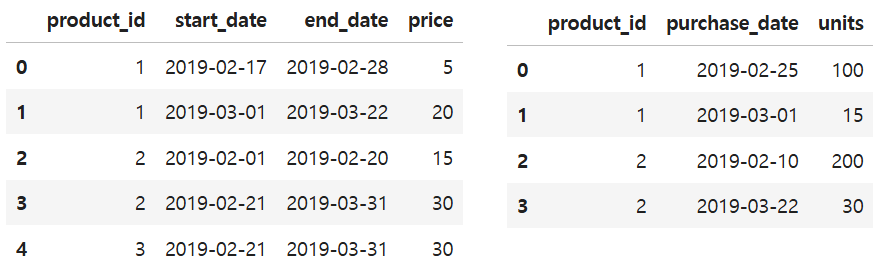
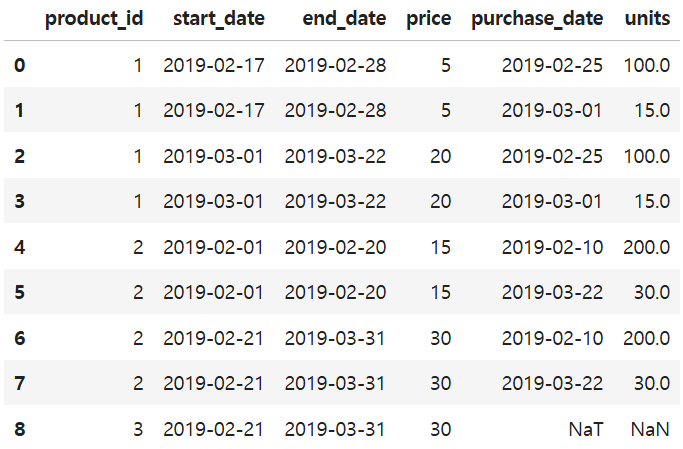
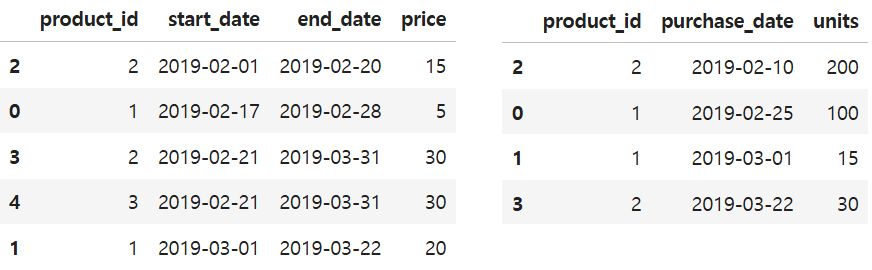
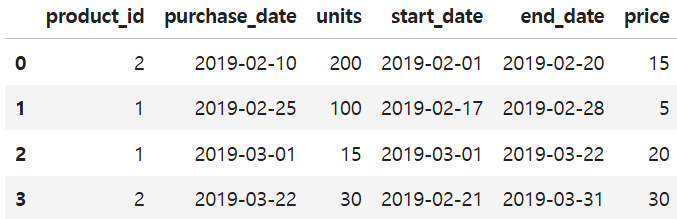
SELECT ROUND(AVG(order_date=customer_pref_delivery_date)*100, 2) AS immediate_percentage
FROM Delivery
WHERE (customer_id, order_date) in (SELECT
customer_id
, min(order_date)
FROM Delivery
GROUP BY customer_id
)
SELECT
ROUND(SUM(order_date=customer_pref_delivery_date AND first_order=1) / COUNT(DISTINCT customer_id) * 100, 2) AS immediate_percentage
FROM
(
SELECT
*
, RANK() OVER(PARTITION BY customer_id ORDER BY order_date) AS first_order
FROM Delivery
) a
SELECT
DATE_FORMAT(trans_date, '%Y-%m') as month
, country
, COUNT(trans_date) AS trans_count
, SUM(IF(state='approved', 1, 0)) AS approved_count
, SUM(amount) AS trans_total_amount
, SUM(IF(state='approved', amount, 0)) AS approved_total_amount
FROM Transactions
GROUP BY 1, 2
2. rating 컬럼이 3 미만인 조건을 통해 불리언 배열을 생성하고 이에 100을 곱해주는 새로운 컬럼을 생성한다. (비율이므로 미리 계산)
3. query_name으로 그룹화한 뒤 두 컬럼을 평균해준다. 반올림도 진행해주는데 아마 틀렸다고 나올 것이다.
4. 이는 판다스의 반올림에는 다른 규칙이 있기 때문인데, 예를들어 소수점 둘째짜리까지 반올림하는 경우 반올림할 숫자가 0.125라면 0.12로 반올림한다. 이는 편향을 줄이기 위한 방법인데 반올림할 값이 딱 중간인 5라면 가까운 짝수로 반올림한다. 그래서 이를 보정해주기 위해 아주 작은 값을 더해줘서 짝수가 아닌 일반적인 방식으로 반올림이 수행되도록 해준다.
SELECT
query_name
, ROUND(AVG(rating / position), 2) AS quality
, ROUND(AVG(IF(rating < 3, 1, 0)) * 100, 2) AS poor_query_percentage
FROM Queries
GROUP BY query_name
SELECT
contest_id
, ROUND(COUNT(user_id)/(SELECT COUNT(user_id) FROM Users)*100, 2) AS percentage
FROM Register
GROUP BY contest_id
ORDER BY percentage DESC, contest_id
# Write your MySQL query statement below
SELECT p.project_id
, ROUND(AVG(experience_years), 2) AS average_years
FROM Project p
LEFT JOIN Employee e
ON p.employee_id = e.employee_id
GROUP BY p.project_id
SELECT s.user_id
, ROUND(AVG(IF(action='confirmed', 1, 0)), 2) as confirmation_rate
FROM Signups s
LEFT JOIN Confirmations c
ON s.user_id = c.user_id
GROUP BY s.user_id
SELECT name
FROM Employee
WHERE id IN (SELECT managerId
FROM Employee
GROUP BY managerId
HAVING COUNT(managerId) >= 5)
-- SELECT e.name
-- FROM Employee AS e
-- INNER JOIN Employee AS m ON e.id=m.managerId
-- GROUP BY m.managerId
-- HAVING COUNT(m.managerId) >= 5
agg 함수와 query 함수에 대해 알아보자.
1. agg 함수
agg 함수는 집계 함수를 적용할 때 사용함. 데이터프레임이나 그룹화된 데이터에 대해 여러 집계 함수를 한 번에 적용할 수 있는 도구임.
주요 특징
1) 하나의 열에 여러 집계 함수 적용 가능
2) 여러 열에 서로 다른 집계 함수 적용 가능
3) 그룹화된(groupby()) 데이터와 함께 사용 가능
문법
DataFrame.agg(func=None, axis=0, *args, **kwrags)
func : 집계 함수 또는 함수의 리스트/딕셔너리. 함수는 문자열이나 python 함수로 전달 가능 ('mean' or np.mean)
axis : 0 이 열기준으로 기본값, 1은 행 기준
반환값은 집계된 결과를 포함하는 DataFrame 또는 Series
1) 단일 열에 여러 함수 적용하려면 함수를 리스트 형태로 전달한다.
result = df['A'].agg(['sum', 'mean', 'max']) # 시리즈 반환
result = df[['A']].agg(['sum', 'mean', 'max']) # 데이터프레임 반환
시리즈라면 시리즈 형태로 반환하고 데이터프레임이면 데이터프레임 형태로 반환한다
2) 여러 열에 동일한 함수 적용
# 모든 열에 대해 'sum' 함수 적용
result = df.agg('sum') # 시리즈 반환 (index가 열)
result = df.agg(['sum']) # 데이터프레임 반환 (index가 함수)
result = df.agg(['sum', 'mean']) # 데이터프레임 반환 (index가 함수)
3) 여러 열에 다른 함수 적용
result = df.agg({'A': 'sum', 'B': 'mean'}) # 시리즈 반환
result = df.agg({'A': ['sum'], 'B': ['mean']}) # 데이터프레임 반환
result = df.agg({'A': ['sum', 'mean'], 'B': ['count','mean']}) # 데이터프레임 반환
{열이름 : 함수} 처럼 딕셔너리 형태로 전달하면 된다. 여러 함수를 전달하려면 딕셔너리 값에 리스트로 감싸서 전달해주면 된다.
4) 그룹화된 데이터에 사용
# group 열을 그룹화한 후 value 열에 sum과 mean 함수 적용
result = df.groupby('group').agg({'value': ['sum', 'mean']})
5) 여러 함수 적용 결과에 새로운 이름 지정
# value 열에 sum 함수를 적용한 열의 이름을 total_sum 로 한다
# value 열에 mean 함수를 적용한 열의 이름을 avg_value 로 한다
result = df.groupby('group').agg(total_sum=('value', 'sum'),
avg_value=('value', 'mean'))
2. query 함수
문자열 기반으로 데이터프레임을 필터링할 수 있는 방법을 제공함 (SQL 스타일의 조건문 사용)
# Write your MySQL query statement below
SELECT stu.student_id
, student_name
, sub.subject_name
, COUNT(ex.subject_name) as attended_exams
FROM Students stu
JOIN Subjects sub
LEFT JOIN Examinations ex
ON stu.student_id = ex.student_id
AND sub.subject_name = ex.subject_name
GROUP BY 1, 2, 3
ORDER BY 1, 3