

susinlee 님의 블로그
[250420] TIL 본문
20대의 마지막 날...
날이 너무나 좋아 집에 있기 아까운 날이었다.
쁨누나가 다같이 카페서 공부하자고 해서 번개팅이 성사되었다.
먼저 도착해서 여러 카페를 알아보다 골목에 괜찮은 카페가 있어 바로 들어갔다.

처음에는 효정이의 밀린 과제 도와주는 걸 계획하고 나갔는데 나 역시도 도움을 받은 느낌이다. 이전에 잘못 해석한 부분들을 수정하며 과제를 완료했고, 그 후 토스 쿼리테스트를 준비하였다. 그러다 쁨누나네 회사서는 어떤 작업을 하는 지 궁금해서 이것저것 물어보기도 했다.
집에서 혼자 공부하는 것보다 집중도 잘되고 재밌었다. 실시간으로 다양한 의견을 접하면서 고민해보는 기회도 얻고, 직접 만나서 하니 ZEP과는 또 다르게 좋았다. 요런 기회를 많이 만들어봐야겠다
과제
과제는 코칭 플랫폼 내 유저 행동 데이터를 분석하여, 합격에 중요한 요인이 무엇인지를 파악하는 것이었다. 코칭 플랫폼의 데이터분석가라고 생각하고 회사에 도움이 될만한 인사이트를 도출해야 한다. 다음은 데이터 메타정보 및 출력 결과(첫 5행)이다.


총 6개의 컬럼이며, 데이터 최소 단위는 유저별로 코칭 신청 이력이다. 다음은 각 컬럼에 대한 설명이다.
- createdat : 코칭을 신청한 시간
- userid : 유저의 고유 아이디
- type : 신청한 코칭의 유형 (resume : 이력서 코칭, interview : 면접 코칭)
- result : 신청한 코칭의 결과 (FAIL, PASS, CANCEL)
- course : 수료한 코스 (NBCamp, Hanghae)
- status : 취업 상태 (취업 준비중, 취업 보류, 최종합격)
합격 여부에 중요한 요인을 알기 위해 데이터 최소 단위를 유저로 만들 필요가 있었다. 유저 별로 어떤 특성(변수)을 만들어 낼 수 있을지, 그 중 합격 여부에 어떤 요인이 영향을 많이 미치는지를 생각해보았다.
변수들을 생성하기 전 전처리를 해줄 필요가 있었다. 날짜 계산을 하기 위해 신청 날짜를 알맞은 타입으로 변경하고, 신청을 했지만 취소한 이력은 어떤 이유에서 취소하였는지 정확히 알 수 없고, 실질적으로 코칭 서비스를 받은 것이 아니기 때문에 해당 정보에서 코칭 플랫폼의 합격 여부를 판별하는 데 노이즈가 될 것으로 판단하여 제거하게 되었다.
# 유저별 기본 user 테이블 생성
user_base = pd.DataFrame(df_valid['userid'].unique(), columns=['userid'])
# datetime 타입으로 변경하기
df['createdat'] = pd.to_datetime(df['createdat'], format='%y/%m/%d %H:%M')
# result가 'CANCEL'인 행 제거하기
df_valid = df[df['result']!='CANCEL'].copy()
첫 번째로 코칭 기간을 구해보자. 코칭 기간이 짧거나 너무 길면 합격율에 영향이 있을 수 있다. 첫 번째 코칭 신청 날짜와 마지막 코칭 신청 날짜의 차이를 코칭 기간으로 정의하고 각 유저별로 코칭 기간을 구해준다.
# 1. 유저별 코칭 기간 (마지막 코칭 신청 날짜 - 첫 코칭 신청 날짜)
# 유저별 신청 날짜별 데이터 정렬하기
created_sorted = df_valid.sort_values(['userid', 'createdat'])
# 유저별 신청기간 테이블 생성
duration = (
created_sorted.groupby('userid')['createdat']
.agg(['first', 'last'])
.assign(duration_days=lambda x: (x['last'] - x['first']).dt.total_seconds() / (60*60*24))
[['duration_days']].round(2).reset_index()
)
duration.head()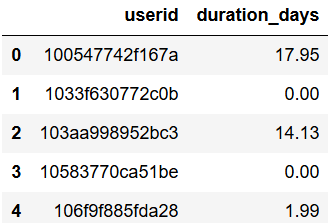
다음으로 이력서 코칭 횟수나 면접 코칭 횟수가 합격 여부에 영향을 주지 않을까? 라는 생각으로 각 코칭 타입별 횟수를 계산해보았다. 직관적으로 코칭 횟수가 적은 것보다 많은 것이 합격에 유리할 것이라 생각된다.
# 2. 유저별 이력서 / 면접 코칭 횟수
coaching_cnt = (
df_valid.groupby(['userid', 'type'])
.size()
.unstack(fill_value=0)
.astype(int)
.reset_index()
.rename(columns={'resume': 'resume_count', 'interview': 'interview_count'})
)
coaching_cnt.head()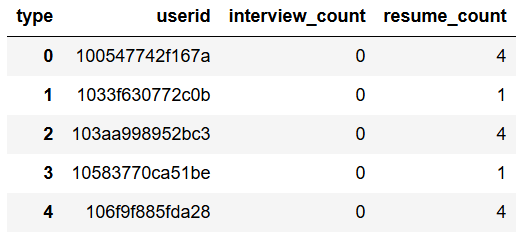
이력서 코칭 횟수나 면접 코칭 횟수도 물론 중요하지만 해당 코칭에서 PASS를 받았는지 받지 못했는지의 여부도 중요할 것이다. 코칭을 아무리 많이 받더라도 피드백을 수용하지 않고 발전이 없으면 도루묵이다. 그래서 각 코칭 별로 PASS 여부를 나타내는 컬럼을 생성해주었다. 코칭 횟수가 양을 나타낸다면 PASS 여부는 코칭의 질을 나타낸다.
# 3. PASS 비율
df_valid['result'] = df_valid['result'].map({'FAIL': 0, 'PASS': 1})
pass_flag_detail = (
df_valid.groupby(['userid', 'type'])['result']
.max() # ✔️ 한 번이라도 PASS 했는지 여부
.unstack(fill_value=0)
.reset_index()
.rename(columns={'resume': 'resume_passed', 'interview': 'interview_passed'})
)
pass_flag_detail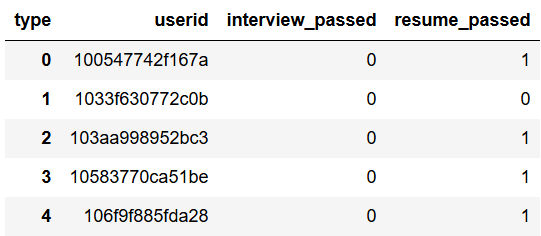
수강 코스에 따른 차이도 있지 않을까라는 고민을 해볼 수 있다. 내배캠과 항해, 총 두 가지의 수강 코스가 존재했고, 유저 별로 어떤 코스를 수료했는지를 나타내는 컬럼을 생성했다.
# 4. course 정보 (0: NBCamp, 1:Hanghae)
course_map = {'NBCamp': 0, 'Hanghae': 1}
df_valid['course'] = df_valid['course'].map(course_map)
course = (
df_valid.groupby('userid')['course']
.first()
.reset_index()
)
course
마지막으로 각 유저의 합격 여부를 나타내는 타겟 변수를 생성해준 뒤 데이터 프레임을 병합하였다.
# 5. 최종 합격 여부
df_valid['target'] = df_valid['status'].apply(lambda x: 1 if x=='최종합격' else 0)
target = df_valid.groupby('userid')['target'].last().reset_index()
# 최종 유저 테이블 병합
from functools import reduce
# reduce는 반복적인 작업을 간편하게 수행해주는 함수다.
# 아래 코드는 user_base부터 순서대로 데이터 프레임을 'userid'를 기준으로 left join해준다.
user_features = reduce(
lambda left, right: pd.merge(left, right, on='userid', how='left'),
[user_base, duration, coaching_cnt, pass_flag_detail, course, target]
)
# 데이터 확인
user_features.head()
시각화 및 통계 분석
각 변수가 합격 여부 별로 어떻게 분포하는 지 시각화해보고, 통계 검정을 진행하였다.
1. 코칭 기간

합격자의 밀도는 불합격자와 다르게 20~60일까지 비교적 평탄하게 이어지는 것을 확인할 수 있다. 더 긴 기간 동안 준비한 수강새이 합격할 가능성이 높은 것으로 보인다. 단, 60일을 넘어가는 시점에서는 합격률이 저조해지는 것을 알 수 있다.t-test 결과 p-value가 0.0000으로 두 집단의 합격률에는 통계적으로 유의미한 차이가 있다.
2. 이력서 코칭 횟수

이력서 코칭 횟수의 경우 전혀 받지 않은 경우를 제외하고는 대체적으로 횟수가 늘어날 수록 합격비율이 증가하는 경향을 보인다.
특히 4회 이상부터 그 경향이 두드러진다. 앞서 언급했듯이 전혀 받지 않은 경우는 반대의 경향을 보였는데, 전혀 받지 않은 경우를 따로 필터링해서 확인한 결과 전부 면접 코칭을 신청한 경험이 있는 수강생들이었다. 면접 코칭은 보통 이력서 코칭 후에 받으므로 이미 이력서가 완벽하게 완성된 수강생들일 것으로 판단된다. 이로 인해 합격률이 상대적으로 높은 것으로 보인다. t-test 결과 p-value가 0.0000으로 두 그룹 간에는 유의미한 평균 이력서 코칭 횟수 차이가 존재한다.
3. 면접 코칭 횟수

면접 코칭까지 진행한 수강생들이 그리 많지 않다는 것을 알 수 있다. 면접 코칭을 받지 않은 유저가 압도적으로 많고, 이 중 대부분이 불합격이다. 한번이라도 진행한 경우 급격하게 합격 유저가 많아지는 것을 확인할 수 있고, 이를 통해 인터뷰 코칭 횟수가 많을수록 합격 가능성이 높아지는 경향이 있음을 알 수 있었다. t-test 결과 p-value가 0.0000으로 두 그룹 간 평균 면접 코칭 횟수에는 유의미한 차이가 있다.
4. 이력서 코칭 통과 여부
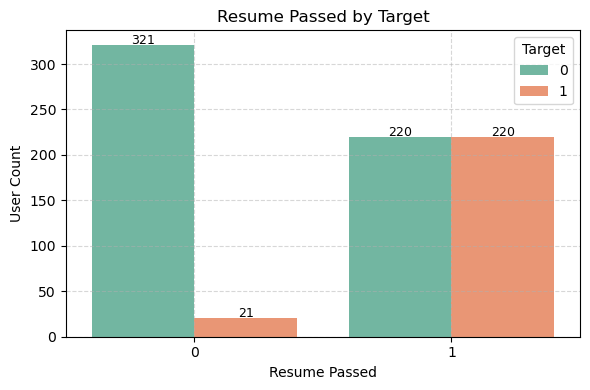
이력서 코칭에서 탈락한 사람은 거의 다 불합격인 것을 확인할 수 있다. 반면 이력서 코칭을 통과한 유저는 합격 비율이 50%로 높아진 것을 확인할 수 있다. 즉, 이력서 코칭 통과 여부는 최종 합격에 필수 조건처럼 작용한다고 판단할 수 있다. 카이제곱 검정 결과 p-value가 0.0000으로 이력서 코칭 통과 여부와 합격 여부는 통계적으로 독립적이지 않다고 할 수 있다.
5. 면접 코칭 통과 여부

면접 코칭을 통과한 유저는 거의 대부분 합격한 것을 확인할 수 있다. 앞서 이력서 코칭 통과여부가 최종 합격에 필수 조건이라면, 인터뷰 통과 여부는 강력한 합격 예측 지표로 보인다. 카이제곱 검정 결과 p-value가 0.0000으로 두 변수는 통계적으로 독립적이지 않다.
6. 수강 코스 종류

내배캠(0)보다 항해(1)의 합격 비율이 더 높은 것을 확인할 수 있다. 항해가 합격 확률을 높이는 데 기여할 수 있다. 카이제곱 검정 결과 p-value가 0.0333으로 유의수준 0.05 하에서 통계적으로 독립적이지 않으나, 앞서 다른 변수들에 비하면 상대적으로 높은 p-value로 합격 여부를 예측하는 데 있어 중요한 요인으로 작용하지는 않을 것 같다.
통계 검정 코드 및 결과
from scipy.stats import chi2_contingency, ttest_ind
import pandas as pd
# [1] duration_days (t-test)
group1 = user_features[user_features['target'] == 0]['duration_days']
group2 = user_features[user_features['target'] == 1]['duration_days']
stat, p = ttest_ind(group1, group2, equal_var=False)
print("🔹 duration_days vs target (t-test)")
print(f"p-value: {p:.4f}")
print("✅ 유의미한 차이 있음\n" if p < 0.05 else "❌ 유의미한 차이 없음\n")
# [2] interview_count (t-test)
group1 = user_features[user_features['target'] == 0]['interview_count']
group2 = user_features[user_features['target'] == 1]['interview_count']
stat, p = ttest_ind(group1, group2, equal_var=False)
print("🔹 interview_count vs target (t-test)")
print(f"p-value: {p:.4f}")
print("✅ 유의미한 차이 있음\n" if p < 0.05 else "❌ 유의미한 차이 없음\n")
# [3] resume_count (t-test)
group1 = user_features[user_features['target'] == 0]['resume_count']
group2 = user_features[user_features['target'] == 1]['resume_count']
stat, p = ttest_ind(group1, group2, equal_var=False)
print("🔹 resume_count vs target (t-test)")
print(f"p-value: {p:.4f}")
print("✅ 유의미한 차이 있음\n" if p < 0.05 else "❌ 유의미한 차이 없음\n")
# 분석 대상 이진형 변수 리스트
binary_vars = ['course', 'interview_passed', 'resume_passed']
for var in binary_vars:
print(f"📊 {var} vs target")
# 1. 카이제곱 검정
table = pd.crosstab(user_features[var], user_features['target'])
chi2, p_chi2, dof, expected = chi2_contingency(table)
print(f" 🔹 카이제곱 검정 p-value: {p_chi2:.4f}")
print("✅ 유의미한 관계 있음" if p_chi2 < 0.05 else " ❌ 유의미한 관계 없음")
# 2. t-test
group0 = user_features[user_features[var] == 0]['target']
group1 = user_features[user_features[var] == 1]['target']
stat, p_ttest = ttest_ind(group0, group1, equal_var=False)
print(f" 🔹 t-test p-value : {p_ttest:.4f}")
print("✅ 평균 차이 있음\n" if p_ttest < 0.05 else " ❌ 평균 차이 없음\n")
통계 검정 코드에 관한 간단 정리
1. ttest_ind : 두 독립된 집단의 평균 차이가 유의한지 검정
from scipy.stats import ttest_ind
t_stat, p = ttest_ind(a, b, equal_var=True, alternative='two-sided')
파라미터
a, b : 두 집단의 수치형 데이터 (리스트 or 배열, 시리즈 등)
equal_var : 두 집단의 분산이 같다고 가정할지 여부
- True(동분산) : Student's t-test
- False(이분산) : Welch's t-test
- 선택하는 쉬운 방법 중 하나로 두 그룹의 분산 비율이 0.5~2 사이이면 동분산, 그렇지 않으면 이분산으로 설정한다.
- 통계적으로는 Levene's test 또는 Bartlett’s test 같은 분산 동질성 검정으로 확인하는 게 정석
alternative : 'two-sided', 'less', 'greater' (양측/좌측/우측 검정 선택)
- alternative='two-sided' : a의 평균과 b의 평균에 차이가 있다를 검정하고자 함
- 귀무가설: a의 평균 = b의 평균
- 대립가설: a의 평균 ≠ b의 평균
- alternative='less' : a의 평균이 b의 평균보다 작다는 것을 검정하고자 함
- 귀무가설: a의 평균 ≥ b의 평균
- 대립가설: a의 평균 < b의 평균
- alternative='greater' : a의 평균이 b의 평균보다 크다는 것을 검정하고자 함
- 귀무가설: a의 평균 ≤ b의 평균
- 대립가설: a의 평균 > b의 평균
내부 동작 방식
- 평균과 표준편차 계산
- 각각의 그룹(a, b)에서 평균, 표준편차, 표본 크기를 계산한다.
- 표준 오차 계산
- SE = sqrt(s1^2/n1 + s2^2/n2)
- 단, equal_var=True이면 공통 분산으로 계산
- t-통계량 계산
- t = (mean1 - mean2) / SE
- 자유도 계산
- equal_var=True : n1 + n2 - 2
- equal_var=False : 웰치 공식 사용
- p-value 계산
- t와 자유도를 기반으로 정규 분포/누적분포를 통해 계산
2. chi2_contingency : 두 독립된 집단의 평균 차이가 유의한지 검정
from scipy.stats import chi2_contingency
chi2, p, dof, expected = chi2_contingency(table, correction=True)
파라미터
table : 교차표 (pd.crosstab() 결과 또는 2D array)
예시)
| 이력서 통과 여부 \ 최종 합격 여부 | 불합격 | 합격 |
| PASS | 321 | 21 |
| FAIL | 220 | 220 |
coreaction : Yabtes의 연속성 보정 적용 여부 (2x2일 때 True 권장. 즉, 두 범주형 변수 모두 2개의 값만 가질 때)
내부 동작 방식
- 입력 교차표 사용
- 각 셀의 실제 관측값 (O_ij)
- 기대도수 계산
- E_ij = ( row_sum_i * col_sum_j ) / total_sum
- 카이제곱 통계량 계산
- χ² = Σ((O_ij - E_ij)² / E_ij)
- 만약 correation=True이고 2x2 표이면 Yates 보정 적용 : χ² = Σ((|O_ij - E_ij| - 0.5)² / E_ij)
- 작은 샘플에도 과도한 유의성 방지. 일반적으로 p-value가 더 커짐
- 자유도 계산
- df = (row - 1) * (cols - 1)
- p-value 계산
- 카이제곱 분포의 누적분포함수를 이용해 p-value 도출
모델링
로지스틱회귀와 랜덤포레스트를 활용하여 합격 여부를 예측해보았다.
| 모델 | Accuracy | F1 Score |
| 로지스틱 회귀 | 0.90 | 0.83 |
| 랜덤포레스트 | 0.90 | 0.84 |
→ 두 모델 모두 정확도 기준 0.90으로 높은 예측 성능을 보였다.
로지스틱회귀 모델의 계수(파라미터) 시각화
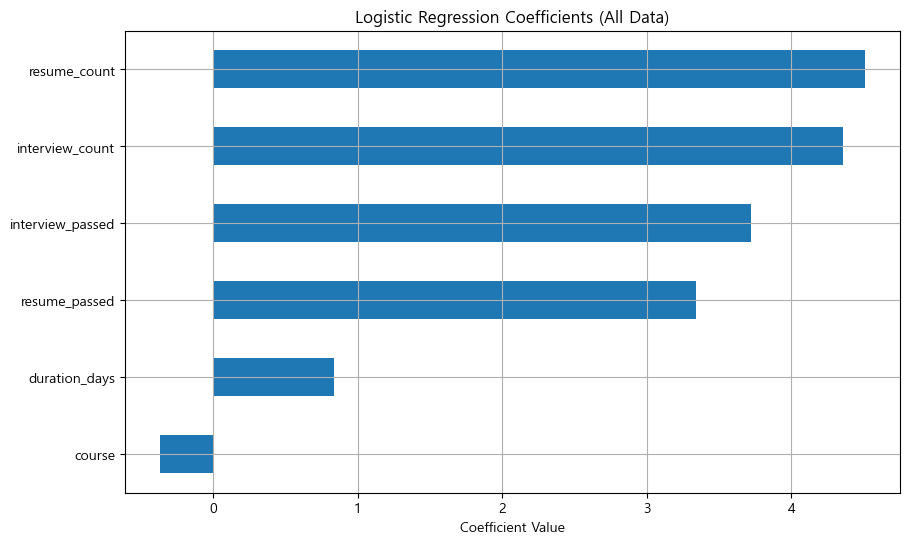
| Feature | Coefficient | Impact |
| resume_count | 4.507659 | ↑ 합격 가능성 |
| interview_count | 4.358725 | ↑ 합격 가능성 |
| interview_passed | 3.723666 | ↑ 합격 가능성 |
| resume_passed | 3.340732 | ↑ 합격 가능성 |
| duration_days | 0.838068 | ↑ 합격 가능성 |
| course | -0.364335 | ↓ 합격 가능성 |
course 변수를 제외한 모든 변수들에서 양의 값을 보였다. 해당 변수들의 경우 값이 커질수록 합격 가능성이 높아짐을 알 수 있다. 그런데 앞서 확인했을 때에는 항해(1)가 내배캠(0)보다 합격률이 높았는데 왜 모델은 항해일 때 합격 가능성을 낮아진다고 학습했을까? 이는 로지스틱 회귀가 단순히 course만 보지 않고 다른 변수들과 함께 고려하기 때문이다.
예를 들어, 내배캠 유저들이 항해 유저들보다 이력서/면접 코칭을 훨씬 많았거나 통과한 비율이 높았을 수 있다. 즉, 모델이 합격 여부를 예측함에 있어 수강 코스 자체보다는, 내배캠 유저들이 보유한 코칭 관련 특성들이 더 큰 영향을 미쳤을 가능성이 있다. 이는 모델이 course 변수의 영향을 음수로 학습한 것이 단순히 수강 코스 때문이 아니라, 기저에 깔린 변수 분포의 차이에 기인한 것일 수 있음을 시사한다.
그래서 두 그룹의 각 지표별 평균을 계산해보았다.

하지만 duration_days(해당 변수의 차이도 미미하다) 변수를 제외하고 '평균'에서는 더 좋은 값들을 가졌고, VIF를 통해 다중 공선성 정도를 측정해보았으나 큰 상관관계를 발견하지는 못하였다. 그럼 왜 course의 계수는 음수일까? 다음과 같은 추측을 해볼 수 있다.
- 다른 변수들에 비해 정보량이 부족
- 단변량과 다변량 분석 간의 차이
- 훈련 샘플 내 클래스 분포 영향
랜덤포레스트 모델의 특성 중요도

랜덤 포레스트 모델은 가장 중요한 변수로 이력서 통과 여부를 꼽았다. 이는 해당 변수가 모델의 분할 기준으로 사용될 때 정보 이득이 가장 컸다는 뜻이다. 그 다음으로는 이력서 및 면접 코칭 횟수가 중요한 변수로 나타났고, 코칭 기간 또한 일정 수준의 기여도를 보였다. 한 편, 수강 코스 변수는 앞서 로지스틱 회귀 분석을 해석하는 과정에서 중요도가 낮다고 판단했는데, 랜덤 포레스트에서도 비슷한 결과를 보였다. 이는 수강한 코스만으로는 합격 여부를 충분히 설명하기 어렵다는 것을 의미한다.
코칭 플랫폼 입장에서 어떤 지표와 시각화 자료를 보면 좋을까?
1. 코칭 횟수와 통과 여부의 관계
- 합격 가능성을 높이는 행동적 요인을 파악
- 예: 이력서 코칭을 3회 이상 받은 유저의 합격률은 몇 %?

2. 각 코칭 단위의 기여도
- 어떤 코칭이 실제로 효과가 있었는지 파악 가능
- 이력서 코칭만 받은 유저 vs 면접 코칭만 받은 유저

3. 유저군 세분화
- 코칭을 많이 받고도 불합격한 유저는 추가 관리 필요

- 1사분면(오른쪽 위)의 유저들은 평균 이상으로 오래, 많이 준비한 유저들로 관리가 필요하다
- 2사분면과 4사분면(오른쪽 아래 / 왼쪽 위)의 유저들은 코칭량-기간 간 불균형이 존재하는 유저로 전략/리소스 분배를 확인한다. 예를 들어, 오른쪽 아래의 경우 오랜 기간 활동했는데 왜 코칭은 적었을까? 라는 의문이 들 수 있고, 이는 리소스 제공이 부족이 원인일 수 있다. 마찬가지로 왼쪽 위의 경우 짧은 기간에 코칭을 몰아서 받았는데 효과적일까? 라는 의문이 들 수 있고, 전략을 다시 설계해야 할 수 있다.
플랫폼 운영 전략 제안 (마무리)
1. 코칭 이력 기반 유저 리포트 생성
- 유저별로 이력서/면접 코칭 횟수와 통과 여부, 합격 확률을 시각화하여 관리자 피드백 제공
2. 경고 알림 시스템 구축
- 코칭을 1회 이하로 받고도 불합격한 유저에게 추가 유도 알림 전송
3. A/B 테스트 설계
- 특정 코칭을 유형을 받은 그룹 VS 받지 않은 그룹 간의 합격률 차이 실험
카페에서 과제를 얼추 마무리한 후 식사를 하러갔다.
근데 쁨누나가 보조배터리를 놓고 왔대서 다시 갔다온다고... 엥? 웬일 하면서도 대수롭지않게 느꼈다.
그러고 5분 뒤 케이크를 땋...
생각도 못한 서프라이즈 생일 축하를 받았다 ! ㅁㄴㅇㄻㄴㅇㄹ

15조에서 펀딩해서 사온 케이크다. 딸기시럽과 생크림이 가득한 케이크다. 집와서 맛있게 먹었다.
번개팅이 잡히고 카페서부터 계획을 했다고 한다. (하지만 전혀 눈치채지 못한 나...)
다시 생각해보면 하나하나가 되게 의심스러운 행동들이 있었는데, 대수롭지 않게 넘긴거 같다. ㅋㅋ
그만큼 15조를 믿었는데 !!.. ㅎㅎ
아무튼 잊지 못할 추억이 될 것 같다~~
15조 다들 너무 고맙고 좋은 일만 가득했음 좋겠다.
(다음 생일날 보자 ^^)
'TIL > TIL' 카테고리의 다른 글
| [250427] TIL (0) | 2025.04.28 |
|---|---|
| [250424] TIL (0) | 2025.04.25 |
| [250416] TIL (0) | 2025.04.17 |
| [250414] TIL (0) | 2025.04.15 |
| [250413] TIL (0) | 2025.04.13 |



