

susinlee 님의 블로그
[250428] TIL 본문
프로젝트 시작 후 이틀 간 데이터 수집 코드를 구현하고 다듬었고, 오늘부터 본격적으로 모델링 작업에 착수했다.
다음과 같이 텍스트 데이터를 넣는다면 긍/부정으로 분류해주는 모델을 사용하려고 한다.

사용할 모델은 FinBERT Korean Sentiment Classification
한국어로 된 금융 문서나 댓글, 뉴스 등을 보고 "긍정/중립/부정" 감성을 분류하도록 파인튜닝(미세조정)된 BERT 모델이다.
프로세스는 다음과 같다.
[Input 문장]
→ [Tokenizer (WordPiece)]
→ [BERT Encoder (multi-head attention)]
→ [CLS 토큰 벡터]
→ [Fully Connected Layer]
→ [Softmax Output (3 classes)]
일반 BERT 모델은 일상 대화, 백과사전, 뉴스 등 범용적 텍스트를 학습했기 때문에 금융 특유의 문장 패턴, 단어 의미를 제대로 이해하지 못한다. 그래서 한국 금융 데이터로 파인튜닝한 모델을 사용했다.
파이썬에서는 HuggingFace Transformers 라이브러리로 쉽게 사용할 수 있다.
from transformers import pipeline
sentiment_pipeline = pipeline(
"sentiment-analysis",
model="snunlp/KR-FinBert-SC"
)
sentiment_pipeline("오늘 삼성전자 주가가 급등했네요")
# 👉 [{'label': 'positive', 'score': 0.98}]
일반 모델과 KR-FinBert 모델의 성능을 비교하기 위해 라벨링된 데이터셋을 만들 필요가 있었다. 그래서 랜덤으로 샘플을 추출해서 직접 글을 읽어가며 분류작업을 진행했다. (200개정도)

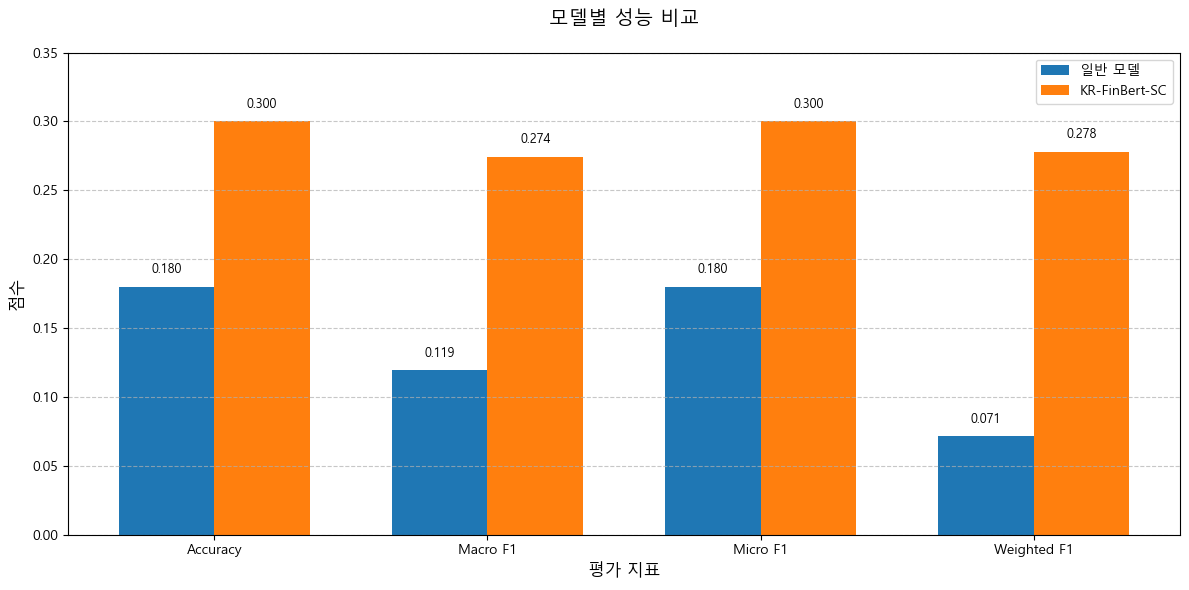
성능 측정 결과 모든 지표에서 일반 모델보다 KR-FinBert 모델이 뛰어났다. 그럼에도 절대적인 수치가 낮았기에 좀 더 파인튜닝이 필요했다.
또 한편으로는 종목마다 업종 차이가 있어 긍정/중립/부정의 요소가 다를 수 있기 때문에 종목별로 파인튜닝을 할 필요가 있었다.
귀찮지만 종목마다 정확한 분류 모델을 얻기 위해서는 라벨링된 데이터셋을 만들어야 한다... ㅜㅜ
우선 종목 하나를 가지고 진행하였다. 라벨링된 데이터셋으로 파인튜닝을 진행한 후 검증 데이터셋에서의 성능을 측정했다.
아래는 일반 Bert, FinBert, 파인튜닝된 FinBert의 성능을 비교해본 그래프다.
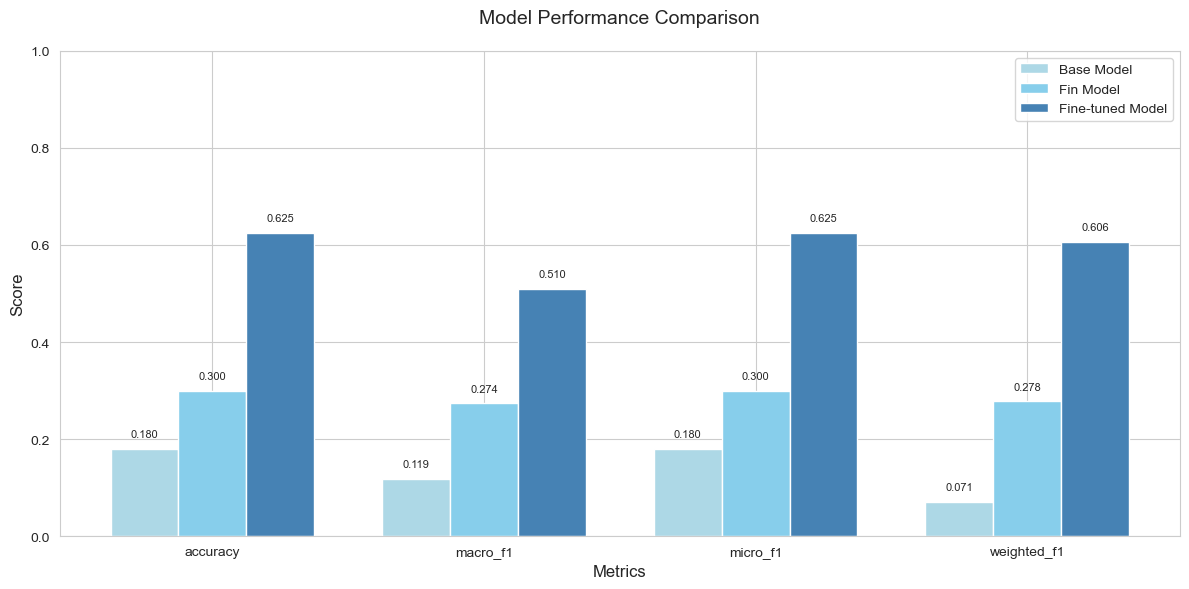
성능 지표가 많이 개선이 됐지만, 그래도 추가적으로 라벨링된 데이터셋을 만들어서 0.7~0.8 수준까지 올린다면 좋을 것 같다.
내일 한번 작업해보자.
최종적으로는 학습된 모델을 가지고 수집한 데이터에 분류작업을 실시하고 분류된 결과를 긍정의 정도를 나타내는 점수(0~100)로 변환한 후 수익률과의 상관관계를 분석해보려고 한다. 물론 주식의 수익률을 예측하는 데 사용할 것이기 때문에 시차를 두고 하루 뒤, 이틀 뒤, ... 일주일 뒤 수익률(혹은 초과수익률)은 어땠는 지를 분석하려 한다.
쇼츠를 보다가 겸손에 대한 이야기가 나왔다. 홍진경이 나와서 자신의 생각을 말하는 데 뭔가 와닿았다.
"사람들에게 굽신거리고 이게 겸손이 아니야. 실패해도 오케이라고 생각하는 것이 겸손함인 것 같애"
특히나 뒤에 문장이 더 마음에 들었다.
실패해도 오케이라는 것은 그 전제가 나는 완벽하지 않다는 것을 받아들이는 것이 아닐까 싶다.
그래서 겸손이라는 표현을 쓰지 않았을까?
나는 실패를 두려워하는 편인 것 같다. 되돌아보면 실패의 두려움에 먹혀 이러지도 저러지도 못했던 날들이 떠오른다.
그래서 그런건지... '그게 겸손하지 못한 태도라고 생각할 수도 있구나' 라는 하나의 관점을 알게되어서 마음에 든걸지도 모르겠다.
겸손하자.

'TIL > TIL' 카테고리의 다른 글
| [250503] TIL (2) | 2025.05.04 |
|---|---|
| [250502] TIL (0) | 2025.05.03 |
| [250427] TIL (0) | 2025.04.28 |
| [250424] TIL (0) | 2025.04.25 |
| [250420] TIL (2) | 2025.04.21 |



